This week I read Monarch paper by Google engineers. The paper covers in detail design decisions involved in building Monarch. Monarch as the title of the paper suggests is an in-memory time series database. It is used by Google monitoring system that monitors most of the Google web properties like Gmail, Youtube, and Google Maps.
Every second, the system ingests terabytes of time series data into memory and serves millions of queries.
These are some very big numbers. Most of us do not have to deal with such large volume of data in our day to day work. Reading this paper can help us understand how engineers building such system make design decisions and tradeoffs.
Monarch Requirements
Before we can understand Monarch in detail it is important to layout expectations from system. The use cases the system need to support are:
- Detecting and alerting when monitored services are not performing correctly
- Displaying dashboards of graphs showing the state and health of the services
- Performing ad hoc queries for problem diagnosis and exploration of performance and resource usage.
The above translates to two quality attributes:
- System should be highly available. It is a write heavy system.
- Data should be queryable. The system should support relational data model and powerful queries.
Along with the above requirements Monarch had to provide following as well well:
- It should be built as a multi-tenant service so that teams can easily use it without the need for maintaining their own instances
- It should support data types such as distribution from sophisticated statistical analysis
- It should support auto sharding
Monarch is in-memory
Monarch stores data in memory to isolate itself from failures at the persistent storage layer for improved availability (it is also backed by log files, for durability, and a long-term repository).
This is important because you want your monitoring system to be highly available. I never thought about in-memory systems in this way before.
Monarch must be low dependency on the alerting critical path. To minimize dependencies, Monarch stores monitoring data in memory despite the high cost.
Monarch favour availability
The CAP theorem by Eric Brewer states that in a distributed shared data system we can only have two out of the three properties (Consistency, Availability, and Partition Tolerance) across a write/read pair.
Monarch’s design is determined by its primary usage for monitoring and alerting. First, Monarch readily trades consistency for high availability and partition tolerance. Writing to or reading from a strongly consistent database like Spanner [13] may block for a long time; that is unacceptable for Monarch because it would increase meantime-to-detection and mean-time-to-mitigation for potential outages.
Monarch drops delayed writes and returns partial data for queries if necessary. In the face of network partitions, Monarch continues to support its users’ monitoring and alerting needs, with mechanisms to indicate the underlying data may be incomplete or inconsistent.
Monarch Architecture: Local and Global
Monarch follow principal of local monitoring in regional zones combined with global management and querying.
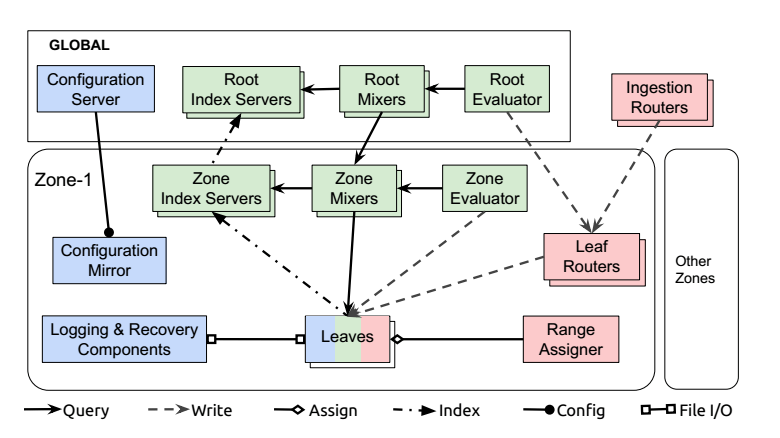
Monarch components can be divided by function into three categories: those holding state, those involved in data ingestion, and those involved in query execution.
The components responsible for holding state are:
- Leaves store monitoring data in an in-memory time series store.
- Recovery logs store the same monitoring data as the leaves, but on disk. This data ultimately gets rewritten into a long-term time series repository.
- A global configuration server and its zonal mirrors hold configuration data in Spanner databases.
The data ingestion components are:
- Ingestion routers that route data to leaf routers in the appropriate Monarch zone, using information in time series keys to determine the routing.
- Leaf routers that accept data to be stored in a zone and route it to leaves for storage.
- Range assigners that manage the assignment of data to leaves, to balance the load among leaves in a zone.
The components involved in query execution are:
- Mixers that partition queries into sub-queries that get routed to and executed by leaves, and merge subquery results. Queries may be issued at the root level (by root mixers) or at the zone level (by zone mixers). Root-level queries involve both root and zone mixers.
- Index servers that index data for each zone and leaf, and guide distributed query execution.
- Evaluators that periodically issue standing queries to mixers and write the results back to leaves.
Data Model
Monarch supports boolean, int64, double, string, distribution, or tuple of other types.
Monarch uses targets to associate each time series with its source entity (or monitored entity), which is, for example, the process or the VM that generates the time series. Each target represents a monitored entity, and conforms to a target schema that defines an ordered set of target field names and associated field types.
Within each zone, Monarch stores time series of the same target together in the same leaf because they originate from the same entity and are more likely to be queried together in a join.
Data storage
Each leaf writes data into its in-memory store and recovery logs. The in-memory time series store is highly optimized: it (1) encodes timestamps efficiently and shares timestamp sequences among time series from the same target; (2) handles delta and run-length encoding of time series values of complex types including distribution and tuple; (3) supports fast read, write, and snapshot; (4) operates continuously while processing queries and moving target ranges; and (5) minimizes memory fragmentation and allocation churn. To achieve a balance between CPU and memory, the in-memory store performs only light compression such as timestamp sharing and delta encoding. Timestamp sharing is quite effective: one timestamp sequence is shared by around ten time series on average.
Queries
There are two kinds of queries in the system: ad hoc queries and standing queries. Ad hoc queries come from users outside of the system. Standing queries are periodic materialized-view queries whose results are stored back into Monarch; teams use them: (1) to condense data for faster subsequent querying and/or cost saving; and (2) to generate alerts. Standing queries can be evaluated by either regional zone evaluators or global root evaluators.
Conclusion
This is dense paper so it requires multiple readings. I got idea on how design decisions are made when building large scale systems. I will keep updating this post as I understand more about the system.
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.
