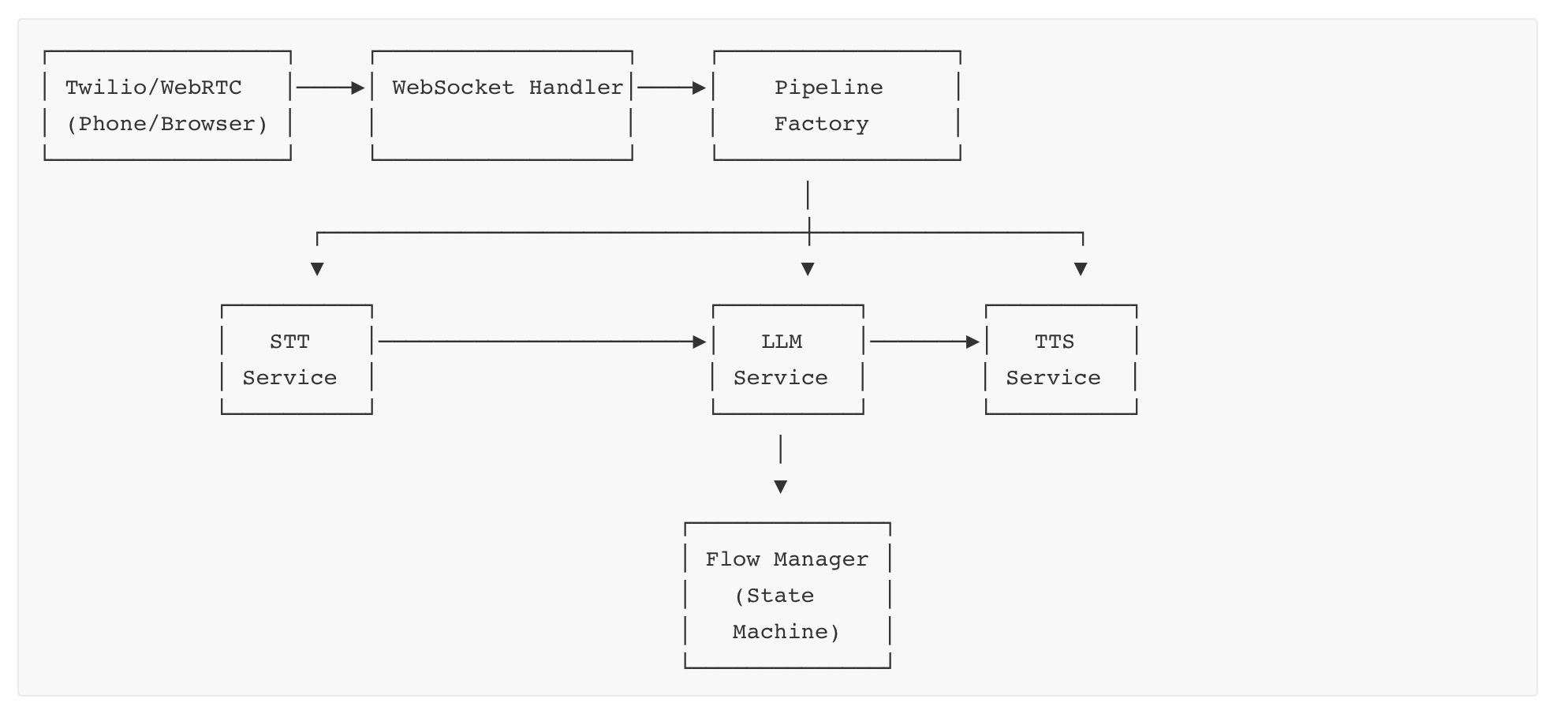
I was reviewing our voice calls today and discovered that in one of voice agents when user was saying “Now” our system was handling it as “No”. After we reset their password we ask them “Would you like to try logging in with this temporary password now, or would you prefer to do it later?”. In many cases when user said Now STT made converted it to No so we ended the call instead of being there with user while they login.
Speech-to-text layer adds failure modes which are frustrating for end users and they start thinking your voice agent is stupid.
If Speech-to-Text layer misheard a single word, then tiny error cascade into a completely broken user experience.
Why This Happens
Speech-to-text systems face a fundamental challenge with words that sound alike. Research on homophone disambiguation shows that while humans use phonetic detail and conversational context to disambiguate similar-sounding words, STT models typically don’t incorporate this linguistic information explicitly. We use Deepgram for STT model.
The problem gets worse in real-world conditions. As noted in Amazon’s research on ASR error detection, speech-enabled agents are vulnerable to errors stemming from misrecognition, and these errors propagate through the system, resulting in unexpected changes in conversation flow.
“Now” and “no” are particularly tricky because:
- They share the same initial consonant
- The vowel sounds are close enough that background noise, microphone quality, or accent variations can blur the distinction
- Both are extremely common words, so the language model doesn’t have strong prior expectations either way
The Fix (That Doesn’t Work)
Your first instinct might be to reach for keyword boosting. This feature lets you tell the model to favor certain words when it’s uncertain. You could boost “now” and hope the model picks it up more reliably.
But here’s the thing: keyword boosting works best for uncommon words, proper nouns, or domain-specific terminology. As the documentation notes, you shouldn’t send common words that the model already handles. “Now” is about as common as words get. Boosting it aggressively risks introducing false positives elsewhere in your transcripts.
Our fix
We applied the fix at the LLM layer so that it becomes smarter about handling ambiguous input. I am still looking if we can use some metadata from Deepgram to make better decision. It is still work-in-progress.
Here’s what we changed:
1. Changed the question we ask user
Users typically reply with what they hear so we changed our question to following. This helps avoid Now in most of the calls.
Would you like to try logging in right away, or would you prefer to try later?
2. Flagged the ambiguous case explicitly
We told the LLM that “no” by itself is suspicious:
HANDLING AMBIGUOUS "NO":
If the user says just "no" without additional context, this is likely
STT mishearing "now". Ask for clarification: "Just to confirm - would
you like to try logging in right away, or save it for later?"
We also updated our function schema to prevent the LLM from proceeding with ambiguous input:
Do NOT call with false if user just said 'no' without context -clarify first.
Why Clarification Beats Assumption
Voice UX research distinguishes between implicit and explicit confirmation. Implicit confirmation keeps things moving but can lead to unrecoverable errors. Explicit confirmation slows things down but catches mistakes.
The conventional wisdom is to use explicit confirmation for high-stakes actions (payments, bookings) and implicit confirmation for low-stakes ones. But there’s a third case that doesn’t fit neatly: when the input itself is unreliable.
In our scenario, asking “Just to confirm…” adds maybe 3 seconds to the conversation. Routing the user down the wrong path means they hang up confused, call back, and start over. The math isn’t close.
The natural flow of conversation already includes methods for “repairing” misunderstandings through repetition and paraphrasing. Your voice agent should do the same.
Broader Lessons
STT errors are systematic, not random
If “now” gets mistranscribed as “no” once, it will happen again. These aren’t one-off glitches. They’re predictable failure modes based on acoustic similarity. Identify them through testing and handle them explicitly.
We recommend simulating background noise during testing specifically to reveal which keywords get dropped or substituted by ASR.
Your LLM is your safety net
LLMs can compensate for ASR errors by using conversational context. The LLM knows what question was just asked. It knows what answers make sense. Use that knowledge.
A bare “no” in response to “would you like to try now or later?” is semantically odd. The user didn’t say “later” or “not right now” or “I’ll pass.” They just said “no.” A well-prompted LLM can recognize this as a signal to seek clarification.
Function schemas are prompts too
If you’re using function calling, the descriptions in your schema are instruction surface area. They influence how and when the LLM invokes functions. We found that adding disambiguation guidance directly to the function description reinforced the behavior we wanted in the task prompt.