The time to read this newsletter is 150 minutes.
The illiterate of the 21st century will not be those who cannot read and write, but those who cannot learn, unlearn and relearn. — Alvin Toffler
- The Hard Truth About Innovative Cultures: 20 mins read. This post answers a question that I was struggling to find the right answer. If there is one post that you should read this week then It should be this one. From the post:
> A tolerance for failure requires an intolerance for incompetence. A willingness to experiment requires rigorous discipline. Psychological safety requires comfort with brutal candor. Collaboration must be balanced with a individual accountability. And flatness requires strong leadership. Innovative cultures are paradoxical. Unless the tensions created by this paradox are carefully managed, attempts to create an innovative culture will fail.
- When AWS Autoscale Doesn’t: 15 mins read. This post by folks at Segment share valuable lessons on AWS autoscaling. The key points for me in the post are:
- AWS autoscaling for ECS follows the formula
new_task_count = current_task_count * ( actual_metric_value / target_metric_value ). The ratioactual_metric_value/target_metric_valuelimit the magnitude of scale out event. To overcome this, you either have to reduce the target value leading to over scale all the time or use custom CloudWatch metric - The default cool down time for scale out event is 3 minutes and cooldown for scale in event is 5 minutes
- AWS autoscaling for ECS follows the formula
- Multiply your time by asking 4 questions about the stuff on your to-do list: 10 mins read. This post won’t tell you how to magically make each day 38 hours long (we’re still working on that). But by assessing our tasks in terms of their significance, we can free up more time tomorrow.
-
Dotfile madness: 10 mins read. I just counted my home directory has more than 30 hidden directories. The post makes a valid argument against proliferation of dot files and dot directories. The author writes:
> Avoid creating files or directories of any kind in your user’s $HOME directory in order to store your configuration or data. This practice is bizarre at best and it is time to end it. I am sorry to say that many (if not most) programs are guilty of doing this while there are significantly better places that can be used for storing per-user program data.
-
Life of a SQL query: 15 mins read. What happens when you run a SQL statement? We follow a Postgres query transformation by transformation as a query is processed and results are returned.
-
Splitting Up a Codebase into Microservices and Artifacts: 10 mins read. This is the first post that you should read if you are thinking about Microservices. I like the way this post first talked about using module boundary to split the code base. If module boundaries are not enough then you should think about Microservices. In my opinion, you should choose Microservices 1) to scale engineering organization 2) the real need for your polyglot environment depending on your business problem.
-
Golang Datastructures: Trees: 20 mins read. This is an awesome read even if you can’t comprehend Golang. This beautifully written post explains how to implement a simple DOM tree in Golang. It shows implementation of breadth first search and depth first search algorithms to implement find functionality. I thoroughly enjoyed this post.
-
Deploying Python ML Models with Flask, Docker and Kubernetes: 30 mins read. This is an extensive tutorial that shows how to deploy Python Flask applications on Kubernetes. It covers how to deploy Machine Learning (ML) models into production environments by exposing them as RESTful API Microservices hosted from within Docker containers, that are in-turn deployed to a cloud environment.
-
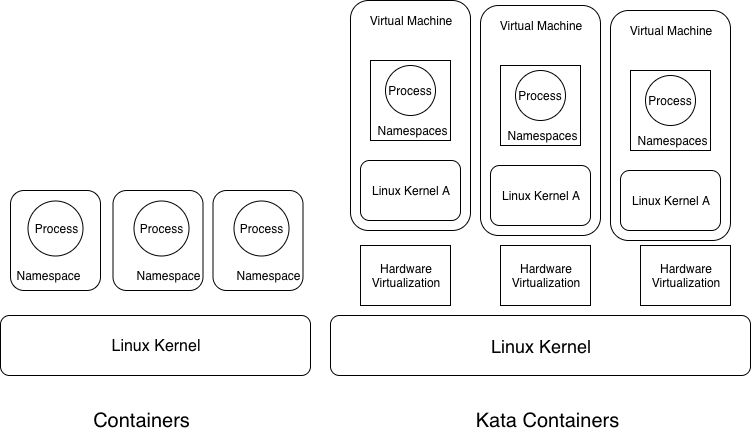
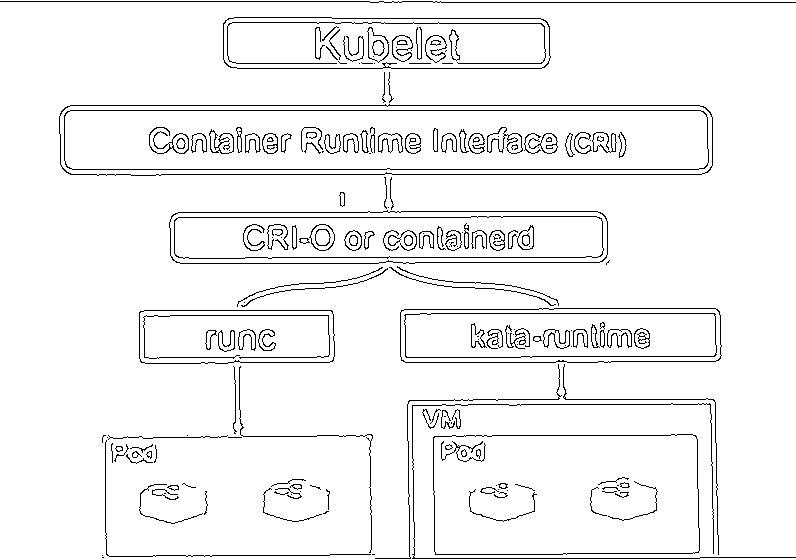
A Minimalistic Guide to Kata Containers: 5 mins read. This is a short post that I wrote about Kata Containers. Kata Containers provide the best of containers and virtual machines. Read the post to learn more.
-
Building a Better Profanity Detection Library with scikit-learn: 15 mins read. This post covers how you can write your own profanity filter using machine learning. The author starts by giving reasons why he didn’t use existing profanity libraries and then he goes over the steps required to create your own profanity detection library.