Most of us are building distributed systems. This is a fact. According to Wikipedia, a distributed system is a system whose components are located on different networked computers, which then communicate and coordinate their actions by passing messages to each other. A distributed system could either be a standard three-tier web application or it could be a massive multiplayer online game.
The goal of a distributed system is to solve a problem that can’t be solved on a single machine. A single machine can’t provide enough compute or storage resources required to solve the problem. The user of a distributed system perceives the collection of autonomous machines as a single unit.
The distributed systems are complex as there are several moving parts. You can scale out components to finish the workloads in a reasonable time. Because of numerous moving parts and their different scaling needs it becomes difficult to reason out the characteristics of a distributed applications. CAP theorem can help us.
The CAP theorem by Eric Brewer states that in a distributed shared data system we can only have two out of the three properties (Consistency, Availability, and Partition Tolerance) across a write/read pair. It was presented by Eric at the Symposium on Principles of Distributed Computing in 2000 . The roots of CAP Theorem are as early as 1998.
- Consistency: Every read is guaranteed to return the most recent write or an error
- Availability: Every request receives a non-error response from a non-failing node in a reasonable time. It is expected that the client may not receive the most recent write
- Partition tolerance: The system continues to operate when network partition happens
In a distributed system, network partition will happen so the choice during network partition is between consistency and availability. This is often perceived in a wrong way that a distributed system can be either of the two; CP (Consistent and Partition Tolerant) or AP (Available and Partition Tolerant). But, this is not true.
In 2012, Eric wrote an article for Computer magazine where he made the following point:
CAP prohibits only a tiny part of the design space: perfect availability and consistency in the presence of partitions, which are rare.
A distributed system can be both consistent and available in the absence of network failure. Only, in the presence of network failure system it has to choose between consistency and availability.
Let’s look at each of the states in action.
Consistent and Available – Forfeit Partition Tolerance
In this state, system is consistent and available when there is no network partition.
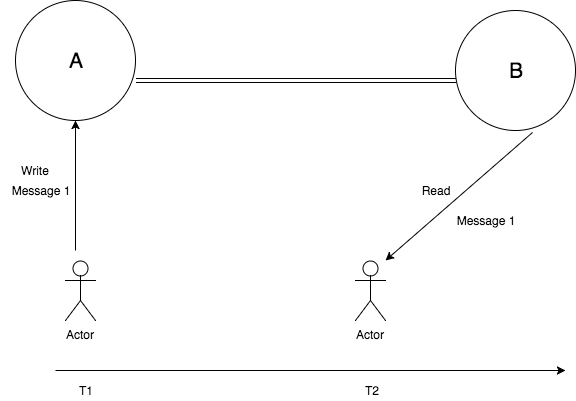
User 1 writes a message “Message 1” to the system at time T1 and user 2 makes a read call to read the message at T2. As there are no network partitions, B should read “Message 1” written by user 1. In this case, system guarantees consistency and availability, but forfeits partition tolerance.
Consistency and Partition Tolerance – Forfeit Availability
In CP system as depicted in the below diagram, the node A and node B can’t talk to each other because of network partition. Therefore, when the client makes a write request to node A it will error out so that the data system remains consistent.
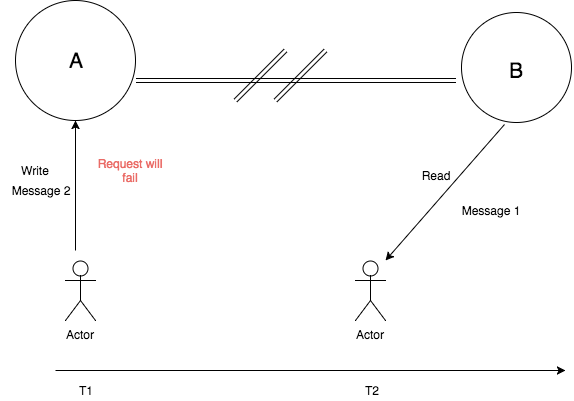
Next, when the client 2 makes a read request it will read previous message 1. The system is consistent as “Message 1” was read since it was the last write that was successful. In this case, system guarantees consistency and partition tolerance, but forfeits availability.
Availability and Partition Tolerance – Forfeit Consistency
In this mode, the client 1 makes a write request to node A. The write request will succeed and the state on node A will be updated to “Message 2”. This change will not be made replicated to node B, which means it will still have old value “Message 1”. Next, when the client 2 makes a read request to node B, then it will get “Message 1” in the response but if the client reads from node A then it will get “Message 2” in response. In this case, the system guarantees availability and partition tolerance, but forfeits consistency. This is depicted in the image below.
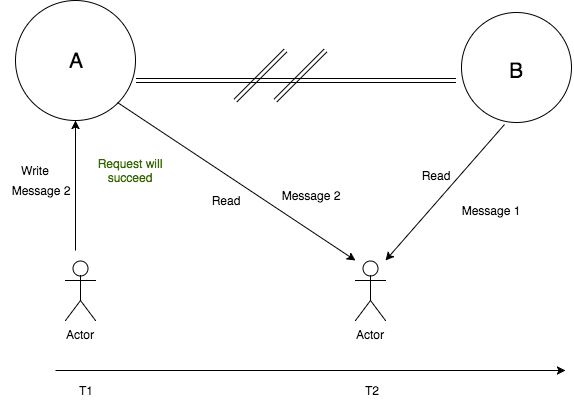
The CAP Theorem Proof
The CAP theorem was initially called Brewer Conjecture, In 2002, Seth Gilbert and Nancy Lynch of MIT published a formal proof of Brewer Conjecture, making it a theorem. Since then, it became CAP Theorem.
Seth and Nancy proved Brewer Conjecture by proof by contradiction. In proof by contradiction, you start by assuming that the opposite proposition is true, and then show that such an assumption leads to a contradiction.
Proof. Suppose that the claim made by CAP Theorem is false. This means there exists a system that can be consistent, available, and partition tolerant at the same time. Let’s start with a system with two nodes A and B. As there is a network partition between the two nodes, they can’t talk to each other as depicted in the image below. Both the nodes have initial state w0.
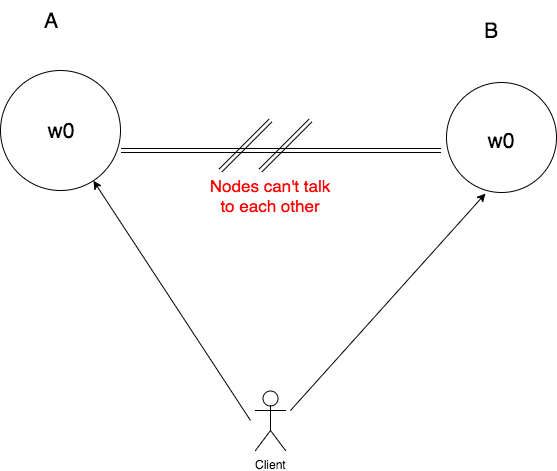
Next, we make our client update the state of node A from w0 to w1. Since, our system is available we should be able to update the state of node A.
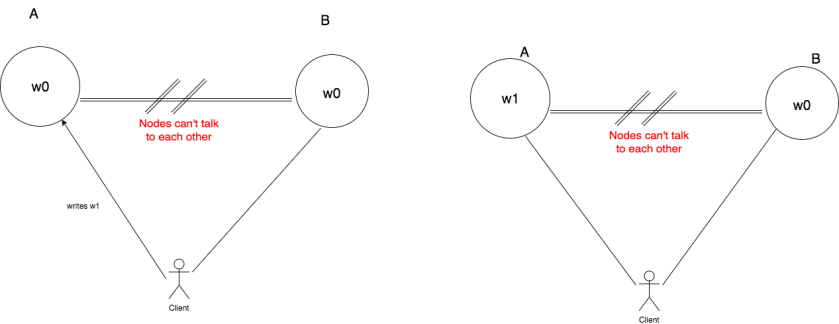
Since, node A and node B can’t talk to each other w1 will not get replicated to node B.
Next, our client will make a read request to node B. The node B being available will respond back. But, it will return value w0 since w1 was not replicated to it.
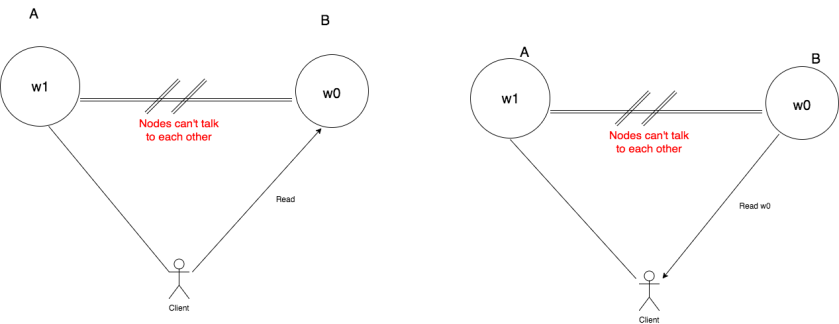
As we can see that node B returns w0 after the client has already written w1 to node A. This means our system is inconsistent. This contradicts our assumption that there exists a system that is consistent, available, and partition tolerant. 
Consistency and Availability are continuous
Many database practitioners have critiqued CAP theorem because they felt many distributed data system developers were misled by the conclusions of CAP theorem. Most developers understood that they have to make a choice between consistency and availability even when there are no network partitions. This has been abused by few NoSQL databases to give up consistency in all scenarios. Giving up consistency often leads to low latency. So, database designers favoured availability over consistency. Eric Brewer wrote an update to his original paper where he clarified the “2 of 3” view and wrote
First, because partitions are rare, there is little reason to forfeit C or A when the system is not partitioned. Second, the choice between C and A can occur many times within the same system at very fine granularity; not only can subsystems make different choices, but the choice can change according to the operation or even the specific data or user involved. Finally, all three properties are more continuous than binary. Availability is obviously continuous from 0 to 100 percent, but there are also many levels of consistency, and even partitions have nuances, including disagreement within the system about whether a partition exists.
What CAP theorem means for application developer?
In my view, as Application developer we have to consider the characteristic of the service we are building and then understand how much consistency we can give up and the kind of availability required from our system. As mentioned above, the consistency and availability properties are continuous rather than binary. The decision on which tradeoff is best for our use case must to be considered carefully. There is no right answer.
For example, if we are building a shopping cart service then our goal should be to ensure that the service is highly available even in case of network partition. The reason for favouring high availability for shopping cart is driven by business. We want to add items to the shopping cart because it produces revenue and keeps our customers happy.
References
- CAP Twelve Years Later: How the “Rules” Have Changed – Link
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.

The PACELC theorem builds on CAP by stating that even in the absence of partitioning, another trade-off between latency and consistency occurs.
Thank you very much for this article! You beautifully covered many things that I had on my mind when I was searching for a CAP article to read!
Some notes and questions!
N. Even I was one of those people who thought the CAP theorem meant I needed to always pick between Consistency and Availability haha. Fortunately, I was corrected by a friend before I made any major mistakes lol.
Q. You touched upon it at the very end, but based on your work experience, do you have any tips for how to decide what trade-offs you need to make? Because I was working on a course project and was asked to prioritize some non-functional requirements and I had no idea how to choose. Is this something that is driven by business? How can we, as engineers, make a call?
Q. In the event of keeping consistency versus availability, is the “write” supposed to fail? What if it passed but the replication failed, and the other nodes are aware of the partition failure and do not return a response? Is it even possible?