
MemSQL is s fast, commercial, ANSI SQL compliant, highly scalable HTAP database. HTAP databases are those that support both OLTP and OLAP workloads. It supports ACID transactions just like a regular relational database .It also supports document and geospatial data types.
MemSQL is fast because it stores data in-memory. But, it does not mean it is not durable. It maintains a copy of data on disk as well. Transactions are committed to the transaction log on disk and later compressed into full-database snapshots. One of the main reason new databases are designed as in-memory first is because memory is getting cheaper every year. It is estimated memory is becoming cheaper 40% every year.
MemSQL has tuneable durability. You can make it fully durable or completely ephemeral. It can be sync or async.
MemSQL simplifies your architecture as you don’t have to write ETL jobs to move data from one data store to another data store. This is the biggest selling point of any HTAP database.
MemSQL supports
- In-memory row storage: It provides optimum real-time performance for transactional workloads. Row storage workloads have a lot of random reads and write. In-memory row storage is a better fit for this use case. MemSQL keeps the whole in-memory row storage workload in memory. OLTP databases for most organisations are under 10TB. This much data can be stored in-memory across multiple nodes. One of thing MemSQL does is that it uses lock free data structures like Skip list to implement rowstore indexes. This makes indexing operations fast and performant.
- On-disk columnar storage: This is best for analytical workloads across large historical datasets. The typical analytical workload involves big sequential scans. This means columnar store will not benefit if it is in-memory. MemSQL keeps metadata in memory skip list. This allows MemSQL to quickly find where to look up data on disk.
MemSQL can ingest data from many different source like Kafka, S3, Spark jobs, Hadoop, relational data warehouse solutions. It has MySQL driver compatible API so you can use your existing tool that supports MySQL. From the MemSQL docs,
MemSQL is not a storage engine or other component of MySQL, nor is MySQL a component of MemSQL, and the MemSQL and MySQL servers do not share any code. The MemSQL server includes its own storage engine and SQL-based execution engine built around scalable distributed execution, lock-free data structures, and machine code generation
MemSQL has inbuilt support for data sharing. As data is ingested it is automatically shared amongst nodes in the cluster. From the MemSQL docs,
Every distributed table (except reference tables, which are replicated in whole on each “leaf” node) has a SHARD KEY that specifies which columns of a row to hash to determine what partition a row should reside in. When rows are inserted into a sharded table, they are hashed by the table’s shard key and sent to the leaf carrying the corresponding partition. This technique is commonly referred to as hash-based partitioning. You can choose how to shard each table by specifying its SHARD KEY as part of the CREATE TABLE statement.
MemSQL uses memory-optimized, lock-free skip lists and hash tables as its indexes. Unlike B+ Trees, these data structures are designed from the ground up to be fast in memory.
MemSQL supports ACID transactions. The isolation level support by MemSQL is READ_COMMITTED. This means during a transaction changes from other committed transactions commit become visible i.e the value of item change during a transaction, if other transactions writes to item and then commit it. You can learn more about ACID transactions in my earlier post — The Minimalistic Guide to ACID Transactions – Link.
Architecture of MemSQL

It has two types of nodes
- Aggregator node: They service request and talk to leaf nodes to get the job done. They also stores metadata related to leaf nodes. You can have more than one aggregator nodes and load can be distributed against them. They are all kept in sync.
- Leaf node: They store the data. All the computations are performed on the leaf nodes. MemSQL scales horizontally by adding more leaf nodes. Clients do not query leaf nodes directly.
Data is replicated between leaf nodes. Leaf nodes can be in different availability zones.
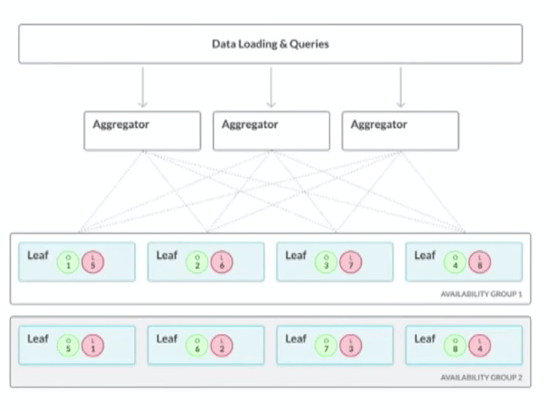
Aggregators are kept in sync.
Data ingestion
MemSQL has built in support for ETL using a feature called MemSQL Pipeline. MemSQL pipelines allow users to ingest data in real-time or in bulk form to MemSQL cluster.
For bulk data load operations, MemSQL offers a LOAD DATA function that imports files in parallel to maximize performance.
Running MemSQL on your machine
The easiest way to try out MemSQL on your machine is using the Docker image available on DockerHub.
You can run MemSQL on your machine by running following command.
docker run -d -p 3306:3306 -p 9000:9000 --name=memsql memsql/quickstart
Once image is pulled and MemSQL is started, you can connect to it using MemSQL shell as shown below.
docker run --rm -it --link=memsql:memsql memsql/quickstart memsql-shell
The memsql-shell is MySQL CLI wrapped in MemSQL clothes.
Let’s create a database and connect to it.
memsql> create database test memsql> use test;
To create rowstore table called company you will run the following SQL command.
CREATE TABLE company( symbol CHAR(5) NOT NULL, name VARCHAR(50), last_sale VARCHAR(10), market_cap VARCHAR(15), IPO_year INT, sector VARCHAR(80), industry VARCHAR(80), summary_quote VARCHAR(50), extra VARCHAR(50) );
To create a columnstore table called trade you will run the following SQL command.
CREATE TABLE trade( id BIGINT NOT NULL, stock_symbol CHAR(5) NOT NULL, shares DECIMAL(18,4) NOT NULL, share_price DECIMAL(18,4) NOT NULL, trade_time DATETIME(6) NOT NULL, KEY(stock_symbol) USING CLUSTERED COLUMNSTORE, SHARD KEY(stock_symbol) );
The main thing to node is the use of CLUSTERED COLUMNSTORE. This tells MemSQL to create columnstore table. If you don’t specify it will be rowstore table.
You can query the data using standard SQL queries. I recommend you follow the MemSQL tutorial to get better hang of it.
Resources
- Video: MemSQL tech talk – Link
- Video: MemSQL ⏩ Accelerate Your Data Infrastructure With A Distributed Architecture Platform – Link
- Text: Hybrid transactional/analytical processing – Link
- Text: Using MemSQL to Query Hundreds of Billions of Rows in a Dashboard – Link
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.

One thought on “MemSQL Introduction: A Hybrid transactional/analytical processing database”