I enjoy working through system design problems. It helps me think how I will design interesting features of various systems. I will post design solutions to interesting problems.
Today, I will share how I will design Amazon recently viewed items page. You can view this page by going to https://www.amazon.com/gp/history/
To me it showed last 73 items I viewed on Amazon.com. I don’t think they are showing last N items rather they are showing items that I viewed in last X days(or months) with some max limit.
Let’s redefine problem now that we better understand it.
Design the Amazon recently viewed items page API. The recently viewed items are all the items that you viewed in the last 6 months. The max count of items could be 100.
Scale of the API
It is important to understand scale of the system as that guide us to make better design decisions.
- Amazon had 300 million users in 2017. We can expect it has added 100 million more users by 2019. So, we can assume it has 400 million users.
- We can expect 10% of these users are active on a given day. This give us 40 million active users
- Amazon.com shows 1 recently viewed item on its home page. This give us 40 million API calls to the recently viewed items page API. But, users typically go to the home page more than once. Let’s assume on average a user views the home page 5 times. So, 40 million * 5 == 200 million API calls. Also, we can assume that 50% of the active users view their history page once in a day. So, total we will have 200 million + 20 million = 220 million calls to the API. I don’t know actual numbers. These are just back of the envelope calculations. This is equivalent to 2500 requests per second.
- The API should send respond under 200 milli seconds.
- I don’t this API is critical so it is fine if it is eventual consistent.
Things to consider
To help us come with the high level design of the API we have to think about the following:
- How will the system know which items are viewed by a user?
- How will data be stored?
- How will data be read by user?
Let’s answer each of them.
How will the system know which items are viewed by a user?
I think the can be solved by publishing an event on a queue when user views an item. I am assuming there will be an item/product service that will help render the product page. This API will publish a ItemViewed event on a queue that will be read by the recently viewed item API.
How will data be stored in the system?
As you might have guessed as well, we only need to provide the read API to the user. We will cover that in next section. I think system will have better scalability characteristics if we separate writes from reads. In the previous section, I said that there will be an event ItemViewed that will be published on a queue. The write side of the API will consume message written to the queue. Writer will read events from the queue and store it in a permanent storage and in-memory storage. The in-memory storage will be used by the read side of the API.
How will data be read by user?
The reads will be performed against an in-memory store that will store items for a user in a descending sorted order. Items stored will be items that were viewed in last 6 months. If number of items stored are greater than 100 then older items will be removed.
High-level Design
Based on the discussion so far I came up with the design shown below.
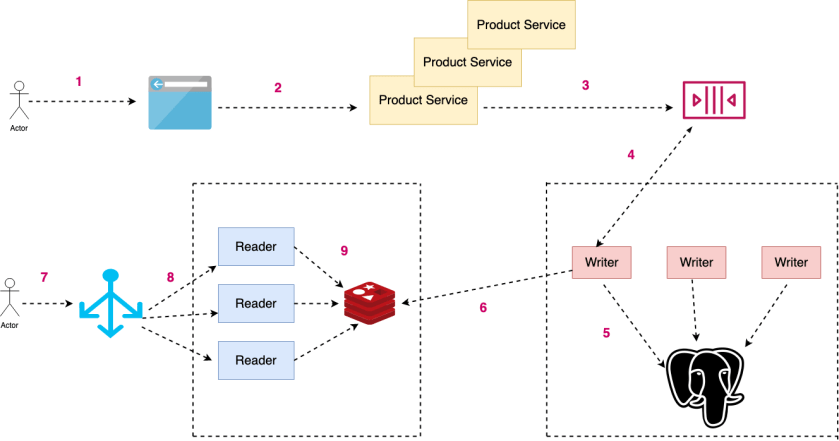
The main technology choices are:
- Messaging queue like ActiveMQ
- PostgreSQL for long term storage and durability
- Redis as in-memory datastore
Let’s go over how the system will work
- User will use their favourite browser to view the products page
-
Product details will be fetched from the product service
-
The Product service will publish an event on the ActiveMQ. The event will have following structure
{ "timestamp": 123456767, "userId": 123, "itemId": 456 } - The writer side of the recently viewed items page service will listen to events
-
The event will be written to PostgreSQL for long term storage. This data can later be used for product recommendations and other Machine Learning activities.
-
Writer will write the event to Redis. Here we will make use of Redis sorted sets to keep latest 100 events produced in last 6 months. We will have one sorted set per user.
-
User makes a request to view the recently viewed items. The request will first hit the load balancer
-
The load balancer will forward the request to any of the reader based on their current CPU utilisation
-
The reader will make a call to the Redis sorted set and return the response
To handle the expected load we will have to run Redis in a clustered mode.
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.

>>”I think system will have better scalability characteristics if we separate writes from reads “”<<
Qstn 1: Can you explain the above in more detail ?
Qstn 2 :If i use Couch base DB , will not the internal cache help me reduce the need of redis as in-memory storage for read ?
Reply will be deeply appreciated. Thanks in advance !!