
This week I was talking to a developer about how to think about data models supported by different databases. One thing that I have learnt in my 15 years of building web applications is that data models play an important role in the success of any software application.
Data model provides an abstract model to organise elements of data and how these elements relate to each other. They describe the structure, manipulation and integrity aspects of the data stored in data management systems such as relational databases. For example, when you are modelling your problem domain in a relational database then you think in terms of real-world entities and how those entities are related with each other. We usually use Entity Relation (ER) diagrams to model tables in relational databases. In this post, we will focus on two popular data models — Relational and Document. We will discuss when you will use one over the other.
Data model influence two main attributes:
- Easy of use: A data model can make some operations easy to achieve and others difficult or impossible
- Performance: A data model can be suitable for faster reads but slower writes or vice versa
Problem Statement
Let’s assume that we have to build a personal online book collection software. The main entities that we care in the book collection software are:
- Author
- Book
- Book Format
- Book Category
- Publisher
The relationship between entities is as mentioned below:
- An author can write multiple books
- A book can have many authors
- A book category can have many books
- A Book can have many categories associated with it
- A book format can have many books
- A publisher can publish many books
Relation Data Model
In relational data model, data is organised into relations (we call them tables in SQL). Tables are unordered set of tuples that stores data in form of rows and columns. Below is the ER diagram of the problem statement we discussed in previous section. We created relations for author, book, publisher, category, and book format.
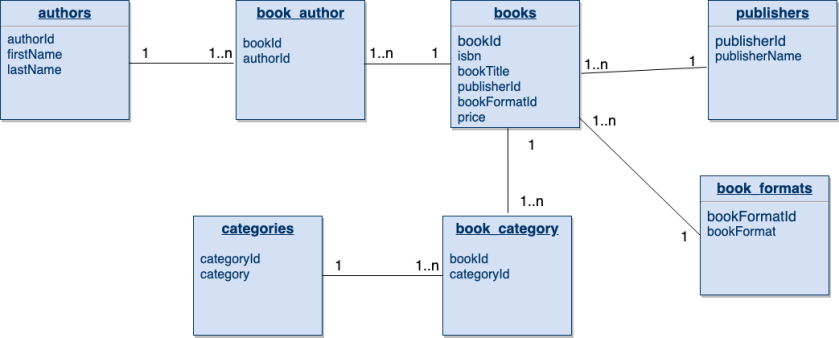
A few points that should be clear from above ER diagram are:
- The One To Many relation is modelled by creating a foreign key in the child many side table. In the above diagram, we can see that A publisher can publish multiple books. The many side books has the
publisherIdcolumn. This makes sense as publishers can’t store multiple book ids. - The Many To Many relation is modelled by creating a mapping table that stores references to both the sides. This is shown in many to many relationship between books and authors and books and categories. In both we created mapping tables —
book_authorandbook_categories.
Document Data Model
Document databases model stores data in the form of documents. Documents are object like structure typically stored as JSON, BSON, XML, or YAML documents, and some can store binary formats like PDF documents. The main advantage of Document stores is that they can store all the data of a given object in the single document unlike RDBMS that spread data across multiple tables. This makes them performant for some use cases. Document data stores have gained a lot of popularity in recent years because of their schemaless nature. Developers are using them to build e-commerce, blogging, and analytics platforms, as well as content management systems.
Many developers have a false notion that they don’t need to do modelling in a document database. It is till important as in relational database as there’s still schema. It is just not enforced.
To model the above problem we can have two documents as shown below.
The Book document stores all the information of the book along with author names and categories.
{
"bookId": "123",
"isbn": "9898989999",
"bookTitle": "Some Book",
"publisherId": "456",
"categories": ["cat1","cat2", "cat3"],
"authors": ["a1","a2","a3"],
"price": 123.5,
"bookFormat": "Kindle"
}
{
"bookId": "221",
"isbn": "98911989999",
"bookTitle": "Some Book 2",
"publisherId": "456",
"categories": ["cat1","cat4"],
"authors": ["a1"],
"price": 120.5,
"bookFormat": "Kindle"
}
The Publisher document stores publisher information.
{
"publisherId": "456",
"publisherName": "Manning"
}
A few points that should be clear from the above JSON documents are:
- We can’t model many to many relations cleanly in the Document databases. We have to duplicate information. Your application tier will have to ensure that content entered is correct and does not have spelling mistakes. All books that have categories and authors will need to store the information with them. If this is a a problem or not depends on the application. If we don’t want to store any extra information about authors and categories then models as sub arrays means we can get all the information in one go. The data storage locality is a big win here
- We can model relationships just like relational databases by storing references. If your document database does not support joins then you have to do joins in the application tier.
In the above example, we made use of both embedding and referencing. It is not easy to decide always which approach to use. Below are some points that might help you decide which approach to take:
We can use embedding when:
- Data from entities are queried together. For example, in our example we always want author name, book format, and categories when we read a book from the data store.
- The lifecycle of the child dependent on the parent.
- The set of values or sub-documents in bounded. We will not have millions of categories for a book.
We can use referencing when:
- One to many relationships are unbounded. For example, if you have a post and comments. You can have as many comments as possible on a post.
- Many to many relations can be better modelled using referencing as shown below.
{
"bookId": "123",
"isbn": "9898989999",
"bookTitle": "Some Book",
"publisherId": "456",
"categories": ["cat1","cat2", "cat3"],
"authorIds": ["1","2","3"],
"price": 123.5,
"bookFormat": "Kindle"
},
{
"bookId": "221",
"isbn": "98911989999",
"bookTitle": "Some Book 2",
"publisherId": "456",
"categories": ["cat1","cat4"],
"authors": ["1"],
"price": 120.5,
"bookFormat": "Kindle"
},
// Author documents
{
"authordId": "1",
"name": "Author 1",
"bookIds": ["123","221"]
},
{
"authordId": "2",
"name": "Author 2",
"bookIds": ["123"]
},
{
"authordId": "3",
"name": "Author 3",
"bookIds": ["123"]
}
Typically, embedding leads to faster reads. Referencing leads to faster writes.
When to use which?
The distinction between document and relational database is blurring. RDBMS have started supporting JSON types and Document stores have started supporting joins and transactions.
You should use relational database when:
- You have to model ManyToMany relations. If you try to model ManyToMany relation in a document database then you will either have to duplicate data or perform joins in your application layer. This usually involve making multiple network request to the document database leading to complicated code and poor performance.
- You have to model a domain that involves structured data that has well defined relations. It turns out most of the applications can be modelled using relational data model. This is the reason relational data model is still the most popular data model and relational database still capture more than half of the database market.
Document databases could be a better choice in the below mentioned situations.
- Document databases have better performance compared to RDBMS when you can model your OneToOne or OneToMany relationships as embedded nested documents. The better performance is achieved due to data storage locality and avoidance of multi-table join. You will typically create embedded nested documents when those documents don’t have identity of their own. It depends on your application domain. In my experience many developers start by using nested embedded documents but soon realise that these nested documents have life of their own and then they normalise them. So, you might not have the performance advantage if in future your requirements change. It is cumbersome to query nested documents.
- Document database supports quick prototyping because of their schemaless nature. This helps make development faster as you don’t have to think about schema migration. You can add a new field to the document and you will not have to make any changes to your existing data. It might lead to some change in your application code but that can be easily managed.
- You are storing data from an external system and you can’t control the structure of the data. Document databases can be a good fit in such scenarios.
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.
