Last year I was building an application that had to process million of records. The processing of each record was independent but complicated. To process all the records it was taking more time than the response time we had to meet as per SLA. We employed near cache and were processing all the data in memory. This made memory utilisation of the app high.
At that time I employed the strategy to shard the data so that each application instance can process a subset of the data. This helped us improve cache utilisation and reduce memory and I/O usage of the application. These days each time scalability is mentioned Microservices is thrown as the solution. We as software developers need to keep in mind three dimensions of scalability so that we can choose the best possible strategy for the problem. These were first mentioned in the book The Art of Scalability. I read this book in 2012 when I was working with OpenShift platform as a service.
As per the book The Art of Scalability there are three dimensions of scalability as shown below
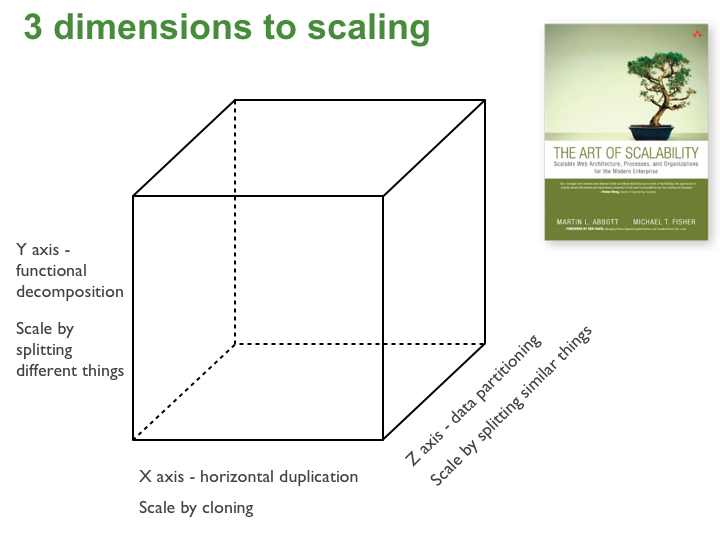
X-axis scaling
This is the traditional way of scaling monolithic applications. We run multiple copies of an application behind a load balancer.
Y-axis scaling
In this model, we break the application vertically into multiple independent services. This is what Microservices architecture allows us to achieve.
Z-axis scaling
In Z-axis scaling each server is responsible for processing subset of the data. This is the solution that I applied for my problem.
In case you want to read more about Scale Cube I suggest you read this post.
