A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable. – Leslie Lamport
Last six months I was building pricing engine for a client. The application was built using multiple components:
- We had a change data capture pipeline built using AWS Kinesis that read data from IBM DB2 and writes to PostgreSQL to keep database in sync with changes happening in the source system
- We were storing denormalised documents in AWS ElastiCache i.e. Redis
- We had a batch job that was doing one time load of the PostgreSQL database
- We had a near cache that helped us process our worst requests in few hundred milliseconds
When you build a system using multiple independent components then you have to keep in mind that you are building a data system that it needs to provide certain guarantees. In our case, we had to guarantee:
- AWS ElastCache i.e Redis will be updated with changes happening in the source system in less than 30 seconds
- Near-cache will be invalidated and updated with latest data so that clients accessing the system will get consistent results. Keeping a global cache like Redis is easier to keep in sync than keeping near-cache in sync. We came up with a novel way to keep near cache in sync with the global cache.
- Data will not be lost by our change data capture pipeline. If processing of a message failed then we retry the message
- There will be times when different data components i.e. PostgreSQL, Redis, and near-cache will have different state. But, eventually it should become consistent
- That there will be a mechanism to observe state of the system at any point of time
Like it or not systems that we are building are becoming more and more distributed. This means there are many more ways they can fail. To help build software systems that meets the end goal, we should keep following three concerns in our mind. These should be defined as clearly as possible so that every team member keep these in mind while building software systems.
- Reliability
- Scalability
- Maintainability
Reliability
In the pricing engine example discussed above, we defined reliability as:
- The pricing engine should calculate correct fare according to the agreed business rules
- All requests to the pricing engine should be fulfilled under a second
- Two same requests happening at the same time should give consistent result
- Pricing engine should continue serving requests even when change data capture pipeline fails. The data that we will return to the client will be consistent but not latest.
Our goal as system designers is to build reliable systems from unreliable components.
One way we add reliability to systems is by redundancy. By running multiple instances of the services in your system, you can increase the reliability. But, you have to design the system keeping in mind that individual instances of the service should be stateless.
You can increase availability of the system by adding more components in parallel as shown in the image below.

As you can see above, when there was a single component availability was 99% but as we increased number of instances of a component then we were able to increase availability to 99.9999%. This can only be possible if services were stateless so you have to keep this in mind while building systems.
Scalability
Scalability is the system’s ability to cope with increased load. Load could mean number of concurrent users, number of concurrent requests, etc. In the pricing engine that we built, we had to support the base load of 1000 requests per second. The system should be able to scale up to peek load of 5000 requests per second. You also have to understand the kind of these requests. The distribution of requests is critical to understand load characteristics of your application.
Once you understand what load your system can expect then you have to look at how different resources of the system behave under that load. This will help you understand characteristics of your application i.e. whether your app is compute intensive or IO intensive. Depending on that, you will decide what kind of resources you need. In our case, application was CPU intensive so we picked AWS instances optimised for compute.
Another thing that go hand in hand with scalability is the response time. The important thing here is to understand the distribution of response time for different percentage of requests.
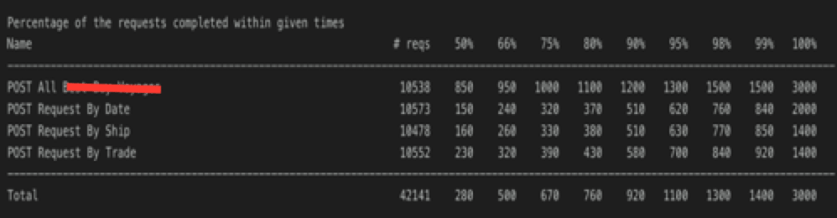
As you can see above, 99% of the requests finished under 1400 milliseconds. There are two requests that took more than 1500 milliseconds. This is the reason the 100 percentile is 3000 milliseconds. Response time is not a single number it is a distribution.
For load testing, I use Locust. Locust is an easy-to-use, distributed, user load testing tool. It is intended for load-testing web sites (or other systems) and figuring out how many concurrent users a system can handle.
Maintainability
The last major concern in building a software system is maintainability. Maintainability is defined as the ease with which system can be maintained over time. The most important aspect of maintainable software is source code. At the source code level, I employ following:
- Clear abstractions and modules. I apply Single Responsibility Principle to ensure we have components that do one thing and one thing well. This also helps in evolving code over time to meet new requirements or fix bugs in existing code.
- Write tests both unit, integration, and acceptance tests. Before you fix a defect, you have to write a failing test.
- Enforce coding standards using Checkstyle.
- All code is merged to master using pull request based code review model. This ensures that at least two people have seen the code before it is merged to master.
- Follow the KISS (Keep it simple and stupid) principle to ensure things are kept as simple as possible
- Writing libraries to share code between different services.
Maintainability also include the ease with which software can be operated in production. This means there should be proper logging and monitoring in place. Monitoring provides visibility into runtime behaviour and internals of the system.
Conclusion
In this post, we covered the fundamentals of building a distributed systems. We covered the three most important concerns that application developers and architects should keep in mind to build software that is reliable, scalable, and maintainable.
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.
