Recently I discovered an interesting project called Kata Containers. It is an open source project hosted by OpenStack foundation. Kata Containers is the merger of Hyper.sh runV and Intel’s Clear Containers.
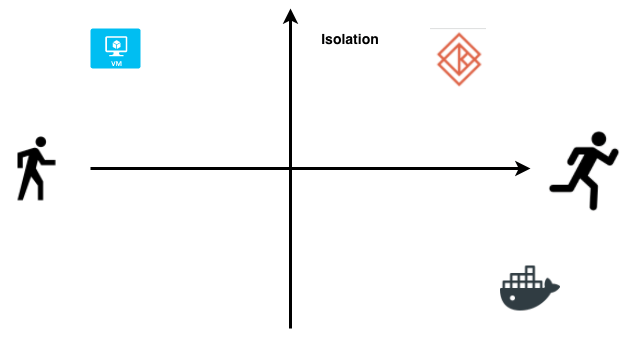
Kata Containers provide the isolations guarantee of a virtual machine and speed and ease of use of containers. As shown in the image below, virtual machines in the top left provide the strictest form of isolation but they are slow to boot up and their size on disk range from 500MB to GBs. On the other hand, containers in the bottom right are fast and nimble but they don’t provide the strictest form of isolation. Kata Containers are best of both worlds. They provide the speed of containers and security and isolation guarantees of virtual machine.
Containers face shared kernel problem, where if on a single host you have multiple containers, if one of those containers gets exploited, you can potentially have access to all the other containers on that host.
Kata Containers are highly optimised virtual machines that run the end user application in a container. So in essence, there is a one-to-one mapping between container and virtual machine as shown below. These virtual machines are lightweight and optimised so you don’t pay the huge cost of running traditional virtual Machines.
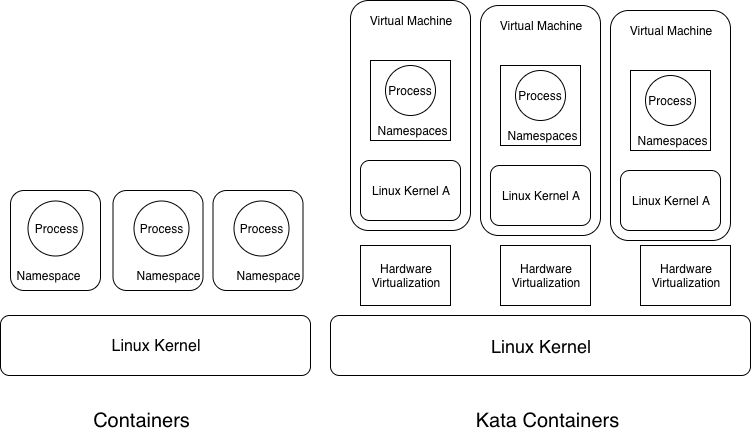
The main difference between containers and kata containers is that containers rely on software virtualisation provided by kernel where as Kata containers rely on hardware virtualisation. Containers for different workloads share the same OS kernel which leads to security and privacy concerns. Kata Containers are addressing this need of securely running disparate workloads. They are fast to boot as the virtual machines use a trimmed down version of OS that’s only responsible for booting the VM and handling over the control to the container.
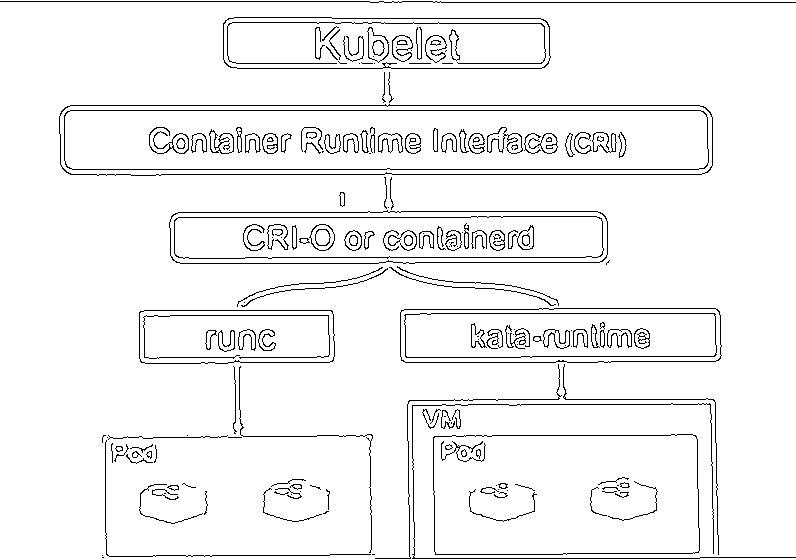
Kata containers are OCI compatible runtime which means you can use them with container orchestration platforms like Kubernetes. The below image shows how Kata Containers will work with Kubernetes.