This is the guide I wish I had when I was starting my Kubernetes journey. Kubernetes is a complex technology with many new concepts that takes time to get your head around. In this guide, we will take an incremental approach to deploying applications on Kubernetes. We will cover what and why of Kubernetes and then we will learn how to deploy a real-world application on Kubernetes. We will first run application locally, then using Docker containers, and finally on Kubernetes. The guide will also cover Kubernetes architecture and important Kubernetes concepts like Pods, Services, Deployment.
In this guide, we will cover following topics:
- What is Kubernetes?
- The real reasons you need Kubernetes
- Kubernetes Architecture
- Deploying a real world application on Kubernetes
What is Kubernetes?
Kubernetes is a platform for managing application containers across multiple hosts. It abstracts away the underlying hardware infrastructure and acts as a distributed operating system for your cluster.
Kubernetes is a greek for Helmsman or Pilot (the person holding the ship’s steering wheels)
Kubernetes play three important roles:
- Referee
- Kubernetes allocates and manages access to fixed resources using build in resource abstractions like Persistent Volume Claims, Resource Quotas, Services etc
- Kubernetes provides an abstracted control plane for scheduling, prioritizing, and running processes.
- Kubernetes provides a sandboxed environment so that applications do not interfere with each other.
- Kubernetes allows users to specify the memory and CPU constraints on the application. It will ensure application remain in their limits.
- Kubernetes provides communication mechanism so that services can talk among each other if required.
- Illusionist
- Kubernetes gives the illusion of single infinite compute resource by abstracting away the hardware infrastructure.
- Kubernetes provides the illusion that you need not care about underlying infrastructure. It can run on a bare metal, in data centre, on the public cloud, or even hybrid cloud.
- Kubernetes gives the illusion that applications need not care about where they will be running.
- Glue
- Kubernetes provides common abstractions like Services, Ingress, auto scaling, rolling deployment , volume management, etc.
- Kubernetes comes with security primitives like Namespaces, RBAC that applications can use transparently
I learnt about the three roles – Referee, Illusionist, and Glue from the book Operating Systems Principles and Practices by Thomas Anderson and Michael Dahlin
Another way to think about Kubernetes is as a platform for building other higher level platforms like OpenShift.
Gartner estimates that 50 percent of companies will use container technology by 2020, up from less than 20 percent in 2017.
In The Rise of Modern Application and DevSecOps report by Sumo Logic it is mentioned that one in three enterprises use managed or native Kubernetes orchestration solutions, and 28 percent of enterprises use Docker containers in AWS.
So far in this guide, we have used the word container multiple times. So, before moving ahead let’s learn about them.
What is a container?
It all started in 2013 when Docker was released as an open source project by dotCloud. At that time, all Platform-as-a-service(or PaaS) providers were trying to find a way to efficiently use hardware in a multi-tenant way. The obvious solution of using virtual machines to run applications in a sandboxed manner didn’t provide the level of hardware utilisation that PaaS providers need to run a successful business. If you read the technical underpinning of early versions of popular PaaS providers like OpenShift, Cloud Foundry, Heroku you will find that they all had their own proprietary mechanism to run applications in a sandboxed manner. OpenShift had something called gears that was glue around SELinux, namespaces, and other linux technologies. Cloud foundry and Heroku had something similar as well.
Then in 2013 Docker was released as an open source project. Its popularity has grown like wildfire since then. If you look at Google trends, you will notice a steep rise in interest for Docker. As you can see in the image below, since 2013 more and more people are searching for docker.
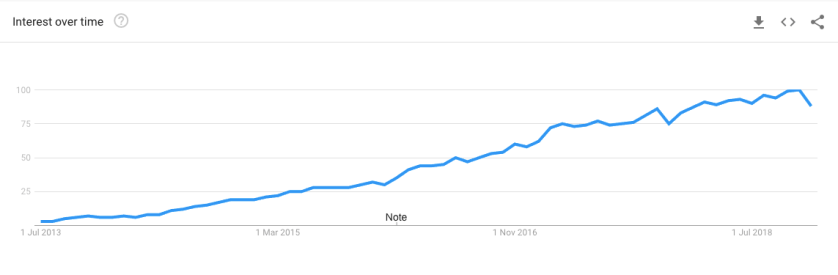
In last 5 years, it has changed the way software applications are deployed and managed. All the PaaS providers re-architected themselves to support Docker. As per wikipedia, Docker is
used to run software packages called “containers”. Containers are isolated from each other and bundle their own application, tools, libraries and configuration files; they can communicate with each other through well-defined channels. All containers are run by a single operating system kernel and are thus more lightweight than virtual machines. Containers are created from “images” that specify their precise contents. Images are often created by combining and modifying standard images downloaded from public repositories.
So, in essence Docker did two things differently that made it accessible to everyone:
- It defined an image format that allows to package contents and share them. Images are static binaries.
- It provides a mechanism to run those images. When a static image is instantiated it become a container.
Containers are not something new. The underlying technologies that make them possible like Cgroups, namespaces, etc. existed since 2008. Docker made containers mainstream by providing the tooling that makes them easy to package and run.
Cgroups: cgroups stands for control groups. Typically, each process thinks it has all memory/CPU time. With cgroups, we can limit, police, and account the resource usage for a set of processes. Cgroups can be manage and monitor following system resources:
- CPU time
- System memory
- Disk bandwidth
- Network bandwidth
- Block IO
Namespaces: It provides each process with its own view of the system. Namespaces limit what you can see. There are multiple namespaces mentioned below. Each process is in one namespace of each type.
- pid
- net
- mnt
- uts
- ipc
- user
The real reasons you need Kubernetes
Following are the 5 reasons why an organization should use Kubernetes.
- Kubernetes makes it easy to manage complex, evolving, and scalable architecture in an automated manner.
- Once you start deploying multiple applications (e.g. Microservices) and need a consistent way for discovery, recovery, deployment, autoscaling, security, etc. for your applications – you need a container orchestration layer to manage them.
- Kubernetes provides higher order constructs for building scalable applications. Some of these are listed below.
- Mounting storage systems
- Replicating application instances
- Horizontal scalability
- Naming and discovery
- Load balancing
- Provides capabilities that you need for running production grade applications
- Distributing secrets without environment variables or storing them in images
- Resource QoS for containers
- Liveness and readiness probes
- Termination and pre-termination messages
- Log access and inspection
- Support for introspection and debugging
- Rolling updates
- Identity and authorization
- Kubernetes abstract away cloud providers so you can migrate relatively easily compared to if you are not using such abstraction.
- It is a single solution for public , private, and hybrid cloud. This reduce risk of Infrastructure lock-in by providing abstractions that enable write once, run anywhere. Kubernetes runs anywhere.
- With Kubernetes, it does not matter if the services are run on-premise, on cloud or in hybrid cloud deployment. It is exactly the same service and the same containers across all. They don’t have to worry if the customer wants to deploy the service over VMware, OpenStack, Azure Stack, AWS or Google Cloud. From the applications and developer’s perspective, it is completely transparent.
- One tool to manage both linux and Windows environments.
- Kubernetes supports wide variety of workloads like Batch, Stateless, Stateful, 12-factor, etc that are typically found in most software organisations. This means you can use a single tool for wide variety of use cases. This gives reusable knowledge/skills that developers can use across different jobs.
- Kubernetes eases the life of operations team.
- It helps ops team by automatically monitoring and rescheduling of the apps in the event of a hardware failure
- The focus of system administrator shifts from supervising individual apps to mostly supervising individual apps to mostly supervising Kubernetes and the rest of infrastructure, while Kubernetes itself take care of the apps
- Kubernetes community is strong and growing. It is the largest open source community. The number of questions asked on Kubernetes on StackOverflow is doubling every year. There are more than 13,000 questions asked on Kubernetes.
Real world application
In this section, we will take a real world application and deploy it to Kubernetes running on your local machine. This section will teach you all the Kubernetes concepts required to kubernetize your web applications.
Let’s start by looking at our real-world application. For this series, I decided to use conduit as the demo application. Conduit is a real world blogging platform similar to Medium.com. Conduit was created by developers part of the realworld community.
RealWorld shows you how the exact same real world blogging platform is built using React/Angular/& more on top of Node/Django/& more. Yes, you can mix and match them, because they all adhere to the same API spec

As you can see in the above graphic, the application is a full blown blogging platform. It has all the features that you can expect in a real world blogging platform. You can signup and signin, publish new blogs, add tags to blog, edit them, follow other people, has a user and global feed, and few other features.
The realworld community publishes back-end and front-end applications written in variety of technologies. For example, there are back-end written in Spring Boot, Node Express, Larvel, Django, and many others. Similarly, there are front-end written in React Redux, Vue.js, Angular, Elm, any many others. For this guide, I decided to use SPA(Single Page Application) front-end written in vue.js and back-end written in Spring Boot. The database for the application is MySQL.
I took source code for front-end and back-end applications and put them in a single repository for this series. This gives me the flexibility to change code as required for this series. All the credit for building conduit application goes to the original authors.
The source code for the application is on Github at shekhargulati/conduit-on-kubernetes.
The source code repository has three directories named:
- conduit-api: This is the Spring Boot MySQL back-end application. The application exposed the REST API as defined by the API spec.
- conduit-frontend: This is the Vue.js based front-end of the application. It makes use of API exposed by the
conduit-api. - k8s: This directory contains Kubernetes resources that we will use later in this guide.
Running application on your machine
Before we can make front-end and back-end application run on Kubernetes it is important to learn how to run these applications locally. So, let’s go over all the steps required to run the full application locally.
We will start by installing all the prerequisites for running application locally. These are:
- You need to have JDK 8 installed on your machine
- You need to have Node and NPM installed on your machine. The version for Node should be above 8.
- You need have MySQL installed on your machine
Running conduit-api on your local machine
Change directory to conduit-api and run the following command to build the application.
./gradlew clean build
If you are on Windows then you need to run gradlew.bat clean build.
The above command will compile the source code, run the tests, and builds an application executable jar in the build/libs directory. The executable jar will be named conduit-api-0.0.1-SNAPSHOT.jar.
You can run the application using the following command:
java -jar build/libs/conduit-api-0.0.1-SNAPSHOT.jar
The above will fail to start the application. You will see following exception in the stack trace.
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Unknown database 'conduit'
The application expects that there will be MySQL database named conduit. It also assumes your database username is root with empty password.
You can configure MySQL related properties in the application.properties file. The default values are shown below.
spring.datasource.url=jdbc:mysql://localhost:3306/conduit spring.datasource.username=root spring.datasource.password=
Change the above values as per your MySQL environment. You need to create a database named conduit in MySQL. Once you are inside MySQL client shell, you can run the following command to create database.
create database conduit;
Now, if you start your application it should start successfully. On successful startup, you should see following two lines in the logs.
2019-01-20 15:26:09.436 INFO 56256 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2019-01-20 15:26:09.440 INFO 56256 --- [ main] io.spring.RealworldApplication : Started RealworldApplication in 6.383 seconds (JVM running for 6.903)
You can test the list articles API by running the following cURL command.
curl http://localhost:8080/api/articles
{"articles":[],"articlesCount":0}
As the database is empty, we received empty response.
Running conduit-frontend on your local machine
Now, that we have our back-end server running on local machine. Let’s go over the steps required to make front-end running on local machine.
Change directory to conduit-frontend.
We will start by installing all the dependencies by running the following command.
npm install
The above command will download all the dependencies required to running the application. These includes Vue dependencies and other dependencies specified in package.json
After all the dependencies are installed you can run the following command to run the application.
npm run serve
The output of the command will be as shown below.
DONE Compiled successfully in 1439ms 3:50:07 PM App running at: - Local: http://localhost:4000/ - Network: http://192.168.1.3:4000/ Note that the development build is not optimized. To create a production build, run yarn build.
The above clearly shows that application is running on http://localhost:4000.
If you go to the http://localhost:4000, you will see following screen.
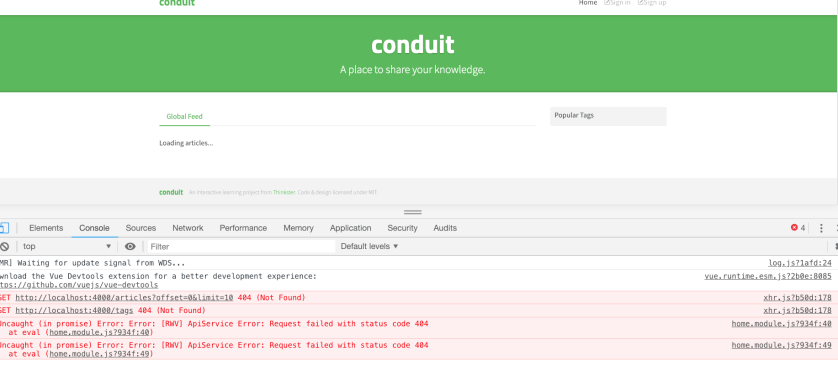
As you can see in the above image, front-end was unable to communicate with the API. The front-end tries to communicate with the back-end server at http://localhost:4000/api. But, as we know from previous section back-end is running at http://localhost:8080/api.
Vue has support for environment variables that it can use at build time. We can pass the API url to it using the environment variables. There are two ways Vue can consume these environment variables. The one way is to create a .env file specific to the environment and tell Vue to use it.
In the conduit-frontend directory, we have a file named .env.dev that defines an environment variable as shown below.
VUE_APP_API_URL=http://localhost:8080/api
In the application code, we use process.env.VUE_APP_API_URL to access the value.
To start the application in dev mode, you run the following command.
npm run serve -- --mode=dev
Now, you will see that front-end application was able to talk to back-end API successfully. You can see the message No articles are here... yet on the screen. When application failed to talk to back-end message was Loading articles...
 ad of long typing
ad of long typing -- --mode=dev each time, you can create a new entry in the scripts object in the package.json
>
"dev": "vue-cli-service serve --mode dev"Now, you can use this to run the application in dev mode
npm run dev
Dockerizing the application
Before we can run the application on Kubernetes we have to dockerize them so that they can be run on Kubernetes. By dockerizing we mean creating Dockerfile for conduit-api and conduit-frontend services. Once you have Dockerfile for services, we can create the images. These images are then run as Docker containers. As mentioned before, Kubernetes is a container orchestration tool. It uses container engines like Docker instantiate containers.
Dockerfile is a text document that contains all the commands a user call on the command-line to assemble an image.
To follow the section, you need to install Docker toolchain on your operating system. We recommend you follow Docker documentation for installation instructions.
Once Docker is installed, you will be able to run the following command and get successful response as shown below.
docker info
Containers: 3 Running: 0 Paused: 0 Stopped: 3 Images: 152 Server Version: 18.09.1 Storage Driver: overlay2 Backing Filesystem: extfs Supports d_type: true Native Overlay Diff: true Logging Driver: json-file Cgroup Driver: cgroupfs // removed rest of output for brevity
Building the Docker container image for conduit-api
To build the container image, we have to write Dockerfile for the service. The Dockerfile for conduit-api is located inside conduit-api/src/main/resources/docker directory. We have integrated building the container image part of the build.
To create Docker container image for conduit-api, you can following command. Please ensure you are inside the conduit-api directory.
./gradlew clean build docker
Once build finishes successfully, you will have Docker image created and published in your local image registry. You can view Docker image by running following command.
docker images
com.conduitapp/api latest 6cf9e8e98186 29 seconds ago 241MB
Let’s understand how container image was created using the Gradle command.
We are using palantir/gradle-docker Gradle plugin to create Docker images using Gradle.
We have added plugin to the build.gradle buildscript section as shown below.
buildscript {
ext {
dockerPluginVersion = '0.21.0'
}
repositories {
maven {
url "https://plugins.gradle.org/m2/"
}
}
dependencies {
classpath("gradle.plugin.com.palantir.gradle.docker:gradle-docker:${dockerPluginVersion}")
}
}
Next, we applied the plugin by adding following line to build.gradle.
apply plugin: 'com.palantir.docker'
Finally, we configured docker task.
docker {
name "com.conduitapp/api"
dockerfile file('src/main/resources/docker/Dockerfile')
files bootJar.archivePath
buildArgs(['JAR_FILE': "${bootJar.archiveName}"])
}
In the docker task configuration shown above we did following:
- We specified name of the Docker image
com.conduitapp/api - We specified location of Dockerfile
- Next, we used
filesparameter to tell that it use the application executable JAR should be included in the Docker build context. - Finally, we
buildArgsto pass arguments to the Docker build command. We are passingJAR_FILEargument with value of the api JAR. This avoids hard coding the name of the JAR in the Dockerfile.
Now, that we know how we have configured docker task let’s look at the Dockerfile.
FROM openjdk:8-jre-slim
ENV SPRING_DATASOURCE_URL jdbc:mysql://mysql:3306/conduit
ENV SPRING_DATASOURCE_USERNAME root
ENV SPRING_DATASOURCE_PASSWORD password
ENV APP_DIR /app
ARG JAR_FILE
ADD ${JAR_FILE} $APP_DIR/app.jar
WORKDIR $APP_DIR
EXPOSE 8080
CMD ["java", "-Djava.security.egd=file:/dev/./urandom", "-jar","app.jar", "spring.datasource.url=${SPRING_DATASOURCE_URL}", "spring.datasource.username=${SPRING_DATASOURCE_USERNAME}","spring.datasource.password=${SPRING_DATASOURCE_PASSWORD}"]
A Dockerfile specifies a list of commands that will executed to create the image.
- A Docker image is based out of other base images. We used
openjdk:8-jre-slimas the base image forconduit-apiapplication. -
Next, we defined
SPRING_DATASOURCE_*environment variables. TheENVinstruction creates environment variables inside the Docker container. These environment variables will override the values specified inapplication.properties. - Then, we used
JAR_FILEargument that we specified inbuild.gradle. We use it to add the api executable JAR to/appdirectory. - Next, we used
EXPOSEinstruction. This command documents that this application runs on port 8080. - Finally, we used
CMDinstruction to specify defaults for an executing container. Using theCMDinstruction, we are specifying how to run the container. We are runningjava -jar app.jarand passing in environment variables we specified above.
We can run the com.conduitapp/api image using the command shown below.
docker run -p 8080:8080 com.conduitapp/api
When you will run the container using the docker run command mentioned above application will fail to start and give following error.
java.net.UnknownHostException: mysql: Name or service not known
The attentive readers would have noticed that api container needs MySQL container to work. As we not running MySQL container, application failed to start.
Let’s run a MySQL container. We can do that by executing following command.
docker run -d --name mysql -e MYSQL_ROOT_PASSWORD=password -e MYSQL_DATABASE=conduit mysql:5.6
If MySQL image is not present on it will be first downloaded.
Once MySQL container has started, you can run the api application again by running the following command
docker run --link mysql:mysql -p 8080:8080 com.conduitapp/api
The above will use the Docker link feature to connect com.conduitapp/api to MySQL container.
This time container will start successfully and you will be able to access the API using tool like cURL.
curl http://localhost:8080/api/articles
{"articles":[],"articlesCount":0}
Building the Docker container image for conduit-frontend
In this section, we will start by creating Docker container image for conduit-frontend.
The Dockerfile for conduit-frontend is shown below.
FROM node:10.15 as builder WORKDIR /home/ui COPY . . RUN npm install ARG VUE_APP_API_URL ENV VUE_APP_API_URL $VUE_APP_API_URL RUN npm run build FROM nginx COPY --from=builder /home/ui/dist /usr/share/nginx/html EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]
The above makes use of the multi-stage build feature of Docker. The first half of the Dockerfile build the artifacts and second half use those artifacts and create a new image from them. We are serving our frontend assets from nginx.
We made use of a build argument VUE_APP_API_URL to specify the location of the back-end API url. The npm run build command makes use of VUE_APP_API_URL to populate process.env object. This is then used by the front-end code process.env.VUE_APP_API_URL to fetch URL of the application at runtime.
To build the production image, you will run the following command. Please ensure you are inside conduit-frontend directory.
docker build --build-arg VUE_APP_API_URL=http://localhost:8080/api -t com.conduitapp/frontend .
Once image is built, you can then run the application using the following command.
docker run -p 80:80 com.conduitapp/frontend
The application will be accessible at http://localhost
Running Kubernetes on your machine
Minikube is a tool geared towards getting people started with Kubernetes. It provides a single command to setup and teardown single node Kubernetes cluster. It is ideal for local development. It supports many of the Kubernetes features that makes sense locally. These features include:
- Networking
- Auto-scaling
- DNS
- Nordports
- Persistent Volumes
- Ingress
- ConfigMaps
- Dashboards
- Container Runtime: Docker, rkt, CRI-O
- Enabling CNI (Container Network Interface)
- LoadBalancer
In this guide, we will not cover Minikube in detail. We will be writing a future guide that will cover Minikube in detail along with its best practices and how it compares with other similar tools. Follow us to be notified.
To install Minikube on your machine, we advice you to follow the official documentation. Along with Minikube, you will also install kubectl. It is a command-line client that we will use throughout this guide to communicate with Kubernetes.
To start a Kubernetes cluster, you will run minikube start command.
Once the Kubernetes cluster is started, you can view the status of the cluster using the following command.
minikube status
host: Running kubelet: Running apiserver: Running kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.106
You can view all the nodes that are part of the cluster by running the following command.
kubectl get nodes
NAME STATUS ROLES AGE VERSION minikube Ready master 1d v1.12.4
Since we are using minikube we only see one node. Minikube runs the Kubernetes cluster on a single node.
At any moment, you can delete the cluster by running the
minikube destroycommand.You can see all the minikube commands by running the
minikube --helpcommand.
Kubernetes Architecture
The image shown below gives a high level overview of different components in Kubernetes architecture.

As shown in the diagram above, Kubernetes architecture is split in two layer:
- Control plane: This layer controls and manage the whole Kubernetes cluster. The API server, Controller Manager, Scheduler, and etcd makes the control plane. All of these run on a single node — the master node.
- Worker nodes: These are the work horse of the Kubernetes cluster. They are responsible for running the applications.
Let’s look at the main component of Kubernetes control plane.
Kubernetes master consists of three processes that run on a single node in your cluster. We call this node master. The three processes are API Server, Scheduler, and Controller Manager. This node is called the master node. You can have multiple master nodes for high availability.
API Server provides the REST API for performing operations on the Kubernetes control plane. These operations include creation of api objects like pods, services, replication controllers, and others. You will be interacting mainly with API using kubectl CLI that you installed earlier. It acts as an entry point to Kubernetes. All interactions happen through API Server.
Scheduler is responsible for scheduling group of container on the worker nodes based on the constraints you have specified in your resource definitions.
Controller Manager is responsible for coordination and health of the entire cluster. It is mainly responsible for tasks like replicating components, bookkeeping of worker nodes, and handing node failures.
etcd is a distributed key value data store. Kubernetes uses etcd for storing cluster state. Any Kubernetes component can query etcd for state of the cluster. It is the single source of truth.
Now, we will look at the main components of the worker nodes layer.
Worker nodes do all the heavy lifting. They are responsible for running the applications we deploy to Kubernetes.
kube-proxy is responsible for maintaining the entire network configuration. It manipulates IP tables on each worker node so that pods and nodes can talk to each other. It is the core networking component of Kubernetes that is responsible for ensuing effective and efficient communication is maintained across the Kubernetes cluster.
Container Runtime is responsible for running the containers. Kubernetes supports Docker, Rocket, etc.
Kubelet is the agent responsible for talking to API and master to report current status of the node.
Container Registry provides storage for container images. It could be a public or private registry like Docker Hub, Quay.io, or registry running inside your cluster, In the image shown above, we have shown container registry outside the cluster but you can have container registry inside the cluster as well.
Learning Kubernetes objects by creating them
In this section, we will take our existing knowledge of containers to next level by deploying the conduit application on Kubernetes. Kubernetes is the tool that can help you run scalable and resilient applications.
When you work with Kubernetes, you use a tool called kubectl. We installed kubectl in a previous step.kubectl is a command-line tool that talks to the Kubernetes REST API and create and manage Kubernetes objects. A Kubernetes object is a persistent entity in the Kubernetes system.
The Kubernetes objects that we will cover in this guide are following:
- Pod
- Service
- ReplicaSets
- Deployment
- Ingress
In this section, we will create different Kubernetes objects to achieve the deployment view shown below.
The client application will make a request and that request will be received by Ingress. Ingress will forward that request to conduit-frontend service. The conduit-frontend service will be backed up pods that will make call to conduit-api service to get the work done. Similar to conduit-frontend, conduit-api is backed by conduit-api pods. These pods will talk to the MySQL service. The difference here is that we are not running MySQL in pods. We will use MySQL running a host and wrap it as a Kubernetes service.

Pod
In Kubernetes, pod is the smallest object that you can create or deploy. Pod is a logical grouping of one or more containers with shared storage/network, and a specification for how to run the containers. In most use cases, you will have one container per pod but for some special use cases you have the flexibility to create and deploy more than one container per pod. Kubernetes will ensure that all the containers in a pod will be scheduled together on the same host.
As mentioned in the previous paragraph, containers in a pod share the same storage and network. This is achieved by configuring container engine to have all containers of a pod share same set of Linux namespaces instead of each container having its own set. You can mount volume to one container and that will be accessible to another container in the same pod. Containers in a pod can communicate with one another using localhost.
One question most developers have hard time understanding is the reason why we pods is the right abstraction instead of containers? There are a couple of good reasons that explains why pod is the right abstraction.
- Pods help you fulfil use cases where a main process need to run one or more complimentary process. These complimentary containers are called sidecar containers. The canonical example of using multiple container per pod is web container render files from a volume that is populated by a sidecar container that updates the files in the volume. Other use case includes data change watchers, log tailers, proxies, etc.
- Pods provides an abstraction over container engines like Docker. This allow Kubernetes to work with other container engines like Rkt.
Each pod can access other pod using its ip address. All pods in a Kubernetes cluster resides in a flat, shared, network-address space.
Let’s look at how to create pods. We will start by creating the pod definition. Below is the pod definition for conduit-frontend .
apiVersion: v1 #1
kind: Pod #2
metadata: #3
name: conduit-frontend
labels:
app: conduit-frontend
spec: #4
containers:
- image: localhost:5000/com.conduitapp/frontend
imagePullPolicy: Always
name: conduit-frontend
ports:
- containerPort: 80
- You start the definition file by specifying the
apiVersion. It defines the versioned schema of the object. Kubernetes server will use this to convert Yaml to the internal value. - The kind field specifies kind of the Kubernetes object that we want to created. In the above definition, we are creating a pod, so we used
Pod. - The third section defines the metadata for the object. Here, we gave name to the Pod
conduit-frontendusing the name attribute. We used labels attribute to attach arbitrary key-value pairs to a resource. Labels will be used later in this guide. - In the fourth section, we specified the desired behaviour of the pod.
- The image attribute specifies name of the container image. The syntax
localhost:5000/com.conduitapp/frontendmeans that we need to get imagecom.conduitapp/frontendfrom the local registry. - Next , we specified
imagePullPolicyto tell Kubernetes that we should always pull image from the container repository. - Next, we defined name of the container.
- Finally, we defined the port at which container is listening. The
conduit-frontendcontainer uses nginx running at port 80 so we used port 80.
- The image attribute specifies name of the container image. The syntax
All the Kubernetes resources are inside the
k8sdirectory. You should change directory to it.
To create conduit-frontend pod, change directory to k8s and run the following command.
kubectl create -f conduit-frontend-pod.yaml
pod "conduit-frontend" created
The above command created the conduit-frontend pod. Do you think it is running? No the pod failed to run because we conduit-frontend pod need to get container image from localhost:5000 container registry. You can view status of the pod by running following command.
kubectl get pod
NAME READY STATUS RESTARTS AGE conduit-frontend 0/1 ImagePullBackOff 0 3s
As you can see, container status is ImagePullBackOff and Ready column shows 0/1 running.
You can push images to Docker Hub or run a registry inside the Kubernetes. In this guide, we will be running Docker image registry inside Minikube.
To run Docker image registry in Minikube, we have to first connect to Docker server running in Minikube. This is accomplished by running following command.
eval $(minikube docker-env)
Now, you are connected to Docker server of Minikube.
Next, we will run Docker image registry by running following command.
docker run -d -p 5000:5000 --name registry registry:2
Now, we have to rebuild images and push them to local Docker registry.
The conduit-api image can be built by running following command. Make sure you are inside conduit-api directory.
./gradlew clean build docker dockerPushLocal
For building conduit-frontend container image and pushing to local registry, we will run following commands. Make sure you are inside the conduit-frontend directory.
docker build --build-arg VUE_APP_API_URL=http://localhost:8080/api -t com.conduitapp/frontend .
Next, we will tag and push the conduit-frontend images to local registry by running following command.
For conduit-frontend, we will run following commands.
docker image tag com.conduitapp/frontend localhost:5000/com.conduitapp/frontend docker push localhost:5000/com.conduitapp/frontend
Now, we have to recreate the pod. We first have to delete the existing pod and then create it
You can delete the pod by running the following command.
kubectl delete pod conduit-frontend
Once deleted, you can create the pod by executing following command.
kubectl create -f conduit-frontend-pod.yaml
You can now view the status of pod by running following command
kubectl get pod
NAME READY STATUS RESTARTS AGE conduit-frontend 1/1 Running 0 1h
As you can see, this time status of the pod is running.
You can also run the kubectl get pod command in watch mode by passing the --watch flag.
To view labels on the pods, you can run the following command.
kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS conduit-frontend 1/1 Running 0 1h app=conduit-frontend
The most important command that you shown know is kubectl describe. The output of this command gives all the details about a Kubernetes resource. To view details of conduit-frontend pod, we will run following command.
kubectl describe pod conduit-frontend
The part of output is shown below.
Name: conduit-frontend
Node: minikube/10.0.2.15
Start Time: Sat, 26 Jan 2019 17:08:11 +0530
Labels: app=conduit-frontend
Status: Running
IP: 172.17.0.4
Containers:
conduit-frontend:
Container ID: docker://6d6629d46065d88b518aa7eef7fd679b741df4472e1118388513cb7840bbb697
Image: localhost:5000/com.conduitapp/frontend
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Sat, 26 Jan 2019 17:08:12 +0530
Ready: True
Restart Count: 0
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
QoS Class: BestEffort
Node-Selectors: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 1h default-scheduler Successfully assigned default/conduit-frontend to minikube
Normal Pulling 1h kubelet, minikube pulling image "localhost:5000/com.conduitapp/frontend"
Normal Pulled 1h kubelet, minikube Successfully pulled image "localhost:5000/com.conduitapp/frontend"
Normal Created 1h kubelet, minikube Created container
Normal Started 1h kubelet, minikube Started container
Let’s look at important parts of the kubectl describe pod command.
- Each pod has a unique IP address. This IP address will be different each time a pod is created.
- Pod status is Running. There are 5 possible values of this field — Pending, Running, Succeeded, Failed, Unknown. You can read more about states in the documentation.
- Pod is not yet restarted so restart count is 0.
- The
Node-Selectorsvalue tells that this pod can be scheduled on any node as the value isnone - The
Eventssection gives details about all the events that have happened in the pod lifecycle so far.
The next question that comes to mind is how to access this pod. The recommend way to access a pod is by creating a new resource of type Service. But, since we have not yet covered services so we will look at quick debugging option. You can access any pod by port forwarding as shown in the image below.
kubectl port-forward conduit-frontend 8000:80
You can view the application running at http://localhost:8000. As conduit-api service is not yet running so application will not do much apart from rendering Vue.js based front-end.
At the moment we have one pod running one container of conduit-api. How can we scale pods? One way could be to create a copy of pod definition and create another pod by running kubectl create command. If we do that then how do we load balance between multiple pods? Luckily, Kubernetes has abstractions like Services, ReplicaSets, and Deployment that will take care of this stuff.
Deployment
In most resources I have read on the web, authors talk about Services after covering Pods. We will take a different approach. We will first cover Deployment object and then cover Services. The reason for this change of order is that you will never create pod as covered in the previous section. You let a controller like Deployment to create and manage Pods for you. There are three controllers that you can use — Deployment, StatefulSet, and DaemonSet. In this post, we will use Deployment controller. The service comes into play when you have multiple copies of a pod and you want to load balance between them.
Deployment controller is used for many use cases as mentioned in the documentation. We will focus on one specific use case of Deployment Create a Deployment to rollout a ReplicaSet .
In future parts of the Kubernetes guide, we will cover all Deployment use cases in detail. Today, we will limit our discussion of Deployment to rollout a ReplicaSet.
We will create a deployment definition for conduit-frontend. The code for conduit-frontend-deployment.yaml is show below.
apiVersion: apps/v1
kind: Deployment
metadata:
name: conduit-fe-deployment
spec:
replicas: 3
selector:
matchLabels:
app: conduit-frontend
template:
metadata:
labels:
app: conduit-frontend
spec:
containers:
- image: localhost:5000/com.conduitapp/frontend
imagePullPolicy: Always
name: conduit-frontend
ports:
- containerPort: 80
In the deployment definition shown above:
- We create a deployment object named
conduit-fe-deployment - We used
replicasto tell Kubernetes that we need to run three replicas of the pod. - The
matchLabelsattribute inselectordefines how Deployment find the pods to manage. We are saying that the deployment will create three replicas of the pod that has labelapp:conduit-frontend. - Finally, in the template section we provide our pod specification. This is equivalent to pod definition we defined in the previous section.
You can delete the pod created in previous section by running
kubectl delete pod conduit-frontend
To create this Deployment, we will run the following command.
kubectl create -f conduit-frontend-deployment.yaml
You can run the kubectl get deployment command to look at the status of deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE conduit-fe-deployment 3 3 3 3 11m
As you can see we desired three replicas for the pod and we currently have three replicas running.
From the Kubernetes Deployment documentation,
DESIREDdisplays the desired number of replicas of the application, which you define when you create the Deployment. This is the desired state.
CURRENTdisplays how many replicas are currently running.
UP-TO-DATEdisplays the number of replicas that have been updated to achieve the desired state.
AVAILABLEdisplays how many replicas of the application are available to your users.
AGEdisplays the amount of time that the application has been running.
We can look at all the objects created by the kubectl create command by running kubectl get all command.
NAME READY STATUS RESTARTS AGE pod/conduit-fe-deployment-85bdb7465d-5456h 1/1 Running 0 15m pod/conduit-fe-deployment-85bdb7465d-65925 1/1 Running 0 15m pod/conduit-fe-deployment-85bdb7465d-v6nsj 1/1 Running 0 15m NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/conduit-fe-deployment 3 3 3 3 15m NAME DESIRED CURRENT READY AGE replicaset.apps/conduit-fe-deployment-85bdb7465d 3 3 3 15m
As you can see in the above output:
- We have three pods running for
conduit-frontend. - We have deployment object
- Finally, we have replicaset object created.
A ReplicaSet is a Kubernetes object that ensures a specified number of pod replicas are running at any given time. Deployment is a higher level concept that manages ReplicaSets so you don’t have to create ReplicaSet yourself. If the pod goes away for any reason then ReplicaSet notices the missing pod and creates a replacement pod.
Services
Services provide the entry point to a set of pods that provide the same functional service. They provide two important functionalities — 1) Service discovery 2) Load balancing between pods. A service gets a fixed IP address and pod that does not change while the service exists. This can be used by pods for communication. In our case, conduit-frontend pods can use IP address of conduit-api service for working with the REST API.
Let’s create a service for the conduit-frontend. The code for conduit-frontend-service.yaml is show below.
apiVersion: v1
kind: Service
metadata:
name: conduit-frontend-lb
spec:
type: LoadBalancer
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: conduit-frontend
- The kind for service is
Service - We used service type to
LoadBalanceras we want to balance load between the pods - The
portspecifies the port on which service will receive requests - The
protocolfield defines protocol used for communication - The
targetPortfield defines the port at which incoming request will be forwarded. This is the port container is running the process. - Finally, we used
selectorfield to define which pods we can target for this service. We used labelapp: conduit-frontend. This means all the pods that have labelapp=conduit-frontend.
If you want all requests made by a certain client to be redirected to the same pod every time, you can set the service’s
sessionAffinityproperty toClientIP.
To create the service, we will execute the following command
kubectl create -f conduit-frontend-service.yaml
service "conduit-frontend-lb" created
We can look at the status of the service by running the following command.
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE conduit-frontend-lb LoadBalancer 10.98.40.101 <pending> 80:32504/TCP 10s
In the command output shown above, External-IP is in pending state. The reason for this is because we are using Minikube. In cloud environment like AWS or GCP, we will get a public IP. This will make our services accessible to the external world.
To access service in Minikube environment, Minikube provide us an easy way to access the service.
minikube service conduit-frontend-lb
Opening kubernetes service default/conduit-frontend-lb in default browser...
This will open the front-end in your browser. Request will be routes to one of the pods serving front-end application.
You can also use minikube service list to view all the services.
|-------------|---------------------|-----------------------------| | NAMESPACE | NAME | URL | |-------------|---------------------|-----------------------------| | default | conduit-frontend-lb | http://192.168.99.107:32504 |
Creating MySQL service
Create a new file conduit-mysql-service.yaml
apiVersion: v1 kind: Service metadata: name: mysql-service spec: type: ExternalName externalName: conduitdb.xxxxxx.ap-southeast-10.rds.amazonaws.com
You can create the service by running following command
kubectl create -f conduit-mysql-service.yaml
Creating deployment and service for conduit-api
Let’s start by creating deployment manifest for conduit-api-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: conduit-api
spec:
replicas: 2
selector:
matchLabels:
app: conduit-api
template:
metadata:
labels:
app: conduit-api
spec:
containers:
- image: localhost:5000/com.conduitapp/api
imagePullPolicy: Always
name: conduit-api
env:
- name: SPRING_DATASOURCE_URL
value: jdbc:mysql://mysql-service:3306/conduit
- name: SPRING_DATASOURCE_USERNAME
value: conduit
- name: SPRING_DATASOURCE_PASSWORD
value: password
ports:
- containerPort: 8080
Next, we will create the deployment object
kubectl create -f conduit-api-deployment.yaml
Then, we will create service object
kubectl create -f conduit-api-service.yaml
Now, we should be able to access the conduit-api
minikube service conduit-api-lb
It will open the page in the browser. You can also use minikube service list to view all the services.
minikube service list |-------------|---------------------|-----------------------------| | NAMESPACE | NAME | URL | |-------------|---------------------|-----------------------------| | default | conduit-api-lb | http://192.168.99.107:31854 | | default | conduit-frontend-lb | http://192.168.99.107:30123 |
Updating conduit-frontend to connect to conduit-api
In the minikube service list output we can see that conduit-api is available at http://192.168.99.107:31854 . We need to publish build the new Docker image and push that to our local registry.
For building conduit-frontend container image and pushing to local registry, we will run following commands. Make sure you are inside the conduit-frontend directory.
docker build --build-arg VUE_APP_API_URL=http://192.168.99.107:31854/api -t com.conduitapp/frontend .
ext, we will tag and push the conduit-frontend images to local registry by running following command.
For conduit-frontend, we will run following commands.
docker image tag com.conduitapp/frontend localhost:5000/com.conduitapp/frontend docker push localhost:5000/com.conduitapp/frontend
Delete the deployment.
kubectl delete deployment conduit-fe-deployment
Create the deployment again
kubectl create -f conduit-frontend-deployment.yaml
Now, you can open the service again using minikube service conduit-frontend-lb. Application will connect to the backend and you will see No articles are here... yet. as shown below. Application is now fully functional.

Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.

Fantastic article, very detailed and well written. Thanks for share!
Wonderful! That’s what I was looking for. Will there be a second part?