I am starting a new blog series (with no end date) from today. In this series, I will pick a topic and go in-depth so that I don’t just scratch the surface of the topic. The goal is to build a habit of learning each week and share it with the community. For the next few months, I will write on different aspects of building distributed systems. Each Wednesday, you may expect a new post.
I am sure we all have built applications where one application uses another application to do its job. Most of the time, applications communicate with each other using HTTP REST API but it can be other communication mechanisms like gRPC, Thrift, Message Queues as well. For example, if you are building an application that needs Twitter service for fetching tweets. To call Twitter API, you will need the API URL and access keys to make a successful API call. Most often we rely on static configuration either in the form of a configuration file or environment variable to get the API URL. This approach works fine when you are working with third party APIs like Twitter as their API URLs do not change often. The static configuration approach fails when we build a Microservices architecture based application. The definition of Microservices that I like is by Martin Fowler as described in his blog,
Microservice architecture style is an approach to developing a single application as a suite of small services, each running its own process and communicating with lightweight mechanisms, often an HTTP resource API.
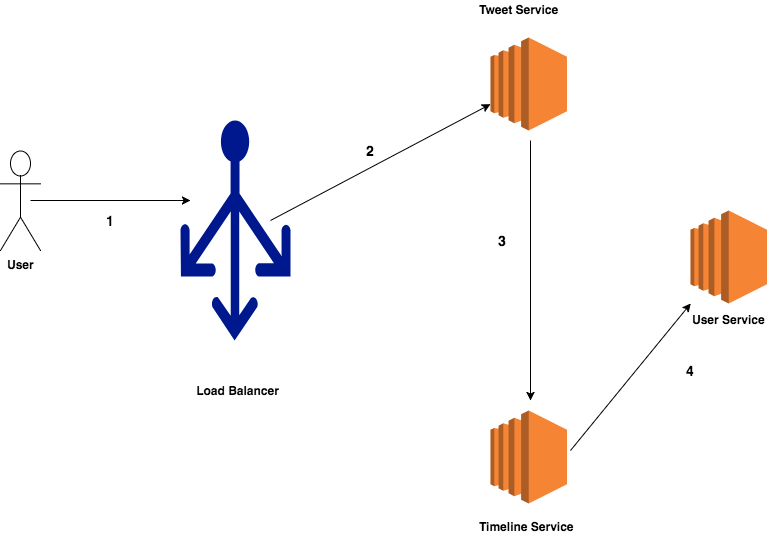
As made clear by the above definition, in Microservice architecture you have a set of smaller services that communicate with each other via some form of HTTP resource API. Let’s assume that you are building a Twitter clone and your Twitter clone has three services — Tweet service, Timeline service, and User service. A user posts a tweet, request after flowing through the Twitter infrastructure reaches the Tweet service which stores the tweet in the database and invoke Timeline service. Timeline fan out the tweet to all the user followers. To know followers of a user, Timeline service makes a query to User service. In this example, Tweet service has to know about Timeline service address and Timeline service has to know about User service address . Assuming these services communicate via HTTP resource API as shown in the diagram below, Tweet service need to know the service URI of the Timeline service for communication. Given that Twitter is a high traffic application, there will be more than a single instance of each service running at a single moment. Also, the number of instances of a service will dynamically change based on the load on the system.
What is Service Discovery?
Service discovery in distributed applications is a general concept where a service makes itself discoverable so that another service can call it by name without knowing its physical location or server address. It solves the problem related to intercommunication between different services.
Approaches to Service Discovery
There are three main approaches to service discovery used in the development community today. Let’s look at them one by one.
Approach 1: Server-side service discovery
In the server-side service discovery each service sits behind a load balancer and client of the service use URI of the load balancer to invoke the service. It is the simplest form of service discovery. In our example, we will have Timeline service that sits behind a load balancer and Tweet service makes a request to the Timeline service via load balancer. It is the responsibility of the load balancer to maintain some sort of registry for storing information about different instances of the Timeline service. This is shown in the image below.
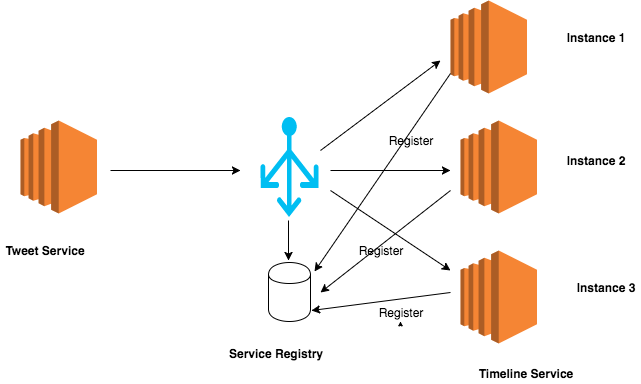
When the request will arrive at the load balancer, it will query its registry to find the node that can handle the request and route request to the available service instance. Requests will be load balanced to three instances of Timeline service. Services will register themselves with the Service registry at startup and de-register themselves at shutdown. One good example of this approach is AWS Elastic Load Balancer. AWS ELB provides health checks and automatic registration/de-registration of backend service in failure cases.
This is the simplest approach for doing service discovery. If your application uses AWS ELB then you can use it for inter service communication as well. Also, this approach is used by popular deployment platforms like Kubernetes or Marathon so you get service discovery for free if you use them.
The main drawback of this approach is that you will be tightly coupled with your deployment platform. If tomorrow, you decide to move out of AWS then either you have to run the load balancer yourself or find a load balancer that does similar job. Also, if you are not using Kubernetes or Marathon then you will not have service discovery in your deployment platform. So, this option will not work for you.
Approach 2: Client-side service discovery
In this approach, the responsibility to find the service instance is inverted. Clients are responsible for determining the network locations of available service instances and load balance requests across them. To find the service instances, clients make a call to something called a service registry. This is a new component that you have to run and manage. Service registry acts like a database that clients can query to fetch details about the available service instances. Once the client knows a set of service instances, it uses a load balancing algorithm to select one of the available service instances and makes a request to it. This is shown in the picture below.

This is the way most client-side service discovery tools work:
- A service is made aware that it needs to register itself with the service registry on instance startup. This usually means sending an HTTP POST request or something similar to the service registry. The service sends its name and address in the request body. When a service instance goes down it makes a de-registration request to the service registry to remove itself from the store.
- Service registry receives the request and stores the instance details. The registry is a key value store so you can get details about the service using the service name as the key.
- The service instance typically periodically(like every 30 seconds) sends a heartbeat to the service registry to refresh their registration. If the service registry does not receive any request for a defined time, it then removes that instance details from its database.
- The service client is also made aware that it needs to get service details from the service registry. The service client usually uses some inter process communication library to make calls to the service.
- This client library receives a set of service instance from the registry and load balance requests across them.
One example of this approach is Netflix Eureka with Netflix Ribbon. Eureka is a service registry that provides a REST API for service registration and querying of the data. Ribbon is an inter process communication (ICP) library with built in software load balancers.
We will look at how we can use Netflix Eureka and Netflix Ribbon for service discovery in a future post, which will be a part of this series.
This approach has benefits like intelligent load balancing at the client side as well as independence from deployment platform and cloud vendor.
There are three drawbacks of this approach – 1) This approach requires that you implement client for each language runtime you work with. Netflix being a JVM shop built most of the libraries for the JVM. If you happen to use some other platform then you might have to write your own libraries. 2) You will have to manage and run s service registry yourself. Service registry needs to be highly available. 3) You start putting all the logic related to service discovery, retry, etc. in your client application. This makes your client fat.
Approach 3: Service mesh
This is the latest approach to service discovery. Service mesh is an abstraction layer on top of deployment platform like Kubernetes for building Microservice architecture based applications. They provide a fabric that handles your service communication. It provides application level services like service discovery on top of a deployment platform like Kubernetes. Service mesh is much more than service discovery.
Most service mesh solutions aim to provide the following features:
- Service to service communication i.e. Service discovery
- Advanced routing
- Auto Retries
- Circuit breaking
- Latency observed load-balancing
- Standardized metrics and logging
- Central control plane
- Distributed tracing
- Rate limiting
- Authentication
Given the drawbacks of the client-side discovery approach, people have been thinking about better approaches to handle these cross-cutting concerns in a programming language in an independent way.
Service mesh is a fat middleware approach. You put the logic of service discovery and retry logic into the networking middleware. This helps keep your clients dumb and language runtime independent.
Service mesh — they are intelligent reverse proxies for Microservices running on a scheduler like Kubernetes. There are three popular solutions in this space.
- Linkerd: It is a Scala based service mesh.
- Envoy: It is created by the folks at Lyft and written in C++.
- Istio: It uses Envoy as proxy to provide more application specific services.
Service mesh like Istio works via a proxy. So, apart from service the node/container also has a proxy installed on it. This is also called sidecar pattern. The proxy intercepts the network requests and forward the request to an appropriate service. This is shown below.

If you were using Netflix OSS then you will have to use many components as defined in the image below.
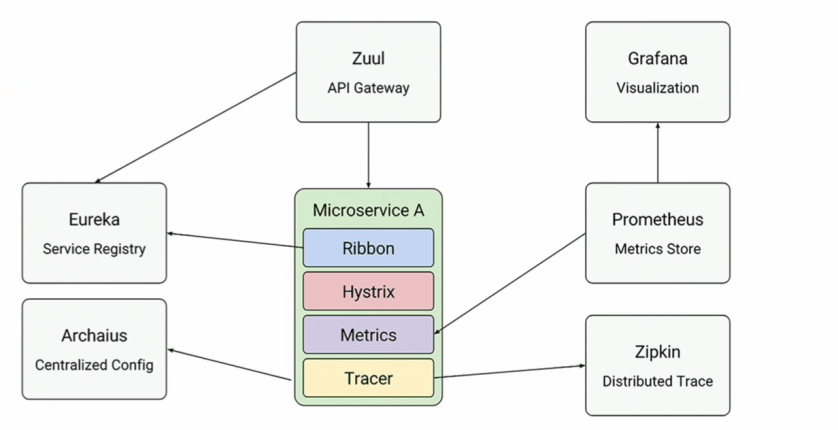
With service mesh it is just the proxy that you need to install alongside your service.
I have no doubt that service mesh is the future infrastructure layer on which we will be building our microservices application. The only drawback that I see is that they couple you to platforms like Kubernetes. To use service mesh, you need to make a bigger investment.
References
- The difference between URLs and URIs https://danielmiessler.com/study/url-uri/
- Microservices https://martinfowler.com/articles/microservices.html
- Service discovery in a Microservices architecture https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/
- Service Meshes https://www.youtube.com/watch?v=hG5k61vXgfo
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.

We’ll explained and described. But I think we are doing multiple overlay networks here. First Kubernetes creates overalay using network plugins and then service mesh uses proxy sidecar doesn’t that makes it more complex and slow?
Yes. It is complex as of now as there is no other alternative approach.