In the last few posts, we looked at various Docker utilities and how XL Deploy can make it easy for enterprises to adopt and use Docker. Docker streamlines software development and testing for teams that have started embracing it. The package once deploy anywhere (PODA) capability of Docker minimises the issue of environmental (like staging, quality assurance, and production) differences.
Docker container wraps software and its dependencies in a filesystem that can be installed on a server. Docker helps to:
- Build: Package an application into an image
- Ship: Share image with others using registries
- Run: instantiate an image into a container
In the last five years, we have seen rapid rise of containers. Containers have become de facto standard for distributing and running software. Container usage along with the Microservice based application architecture has lead to a lot of advancement in the cluster management solutions. Kubernetes, Apache Mesos, Amazon ECS, and Docker Swarm are all trying to solve the problem of running and managing clusters of containers at scale.
In this post, we will start by looking at the history of cluster computing. Then, we will look at different components of a typical cluster manager like ECS. We will end our discussion by going through different ways to implement schedulers. Scheduler makes the actual decision of assigning which machine should run the task.
Cluster Computing
Cluster computing is based on the premise that you can view a set of connected computing machines as a single system. It enables you to abstract CPU, memory, and disk resources allowing for highly efficient usage of nodes in the cluster. This gives you a multi-tenant computing environment that has better performance, availability, and reliability characteristics as compared to a single machine. These clusters can run applications ranging from high traffic e-commerce website to a highly performance database engine.
There are a number of benefits of computing clusters. Some of these are:
- Reduced cost
- More processing work
- Scalability
- Availability
Cluster computing is not a new concept. It has existed in some share or form for close to 50 years. The earliest reference of cluster computing is in the seminal paper on parallel computing Amdahl’s Law by Gene Amdahl of IBM. The first commercial clustering product was Attached Resource Computer(ARC) system, developed in 1977.
The statically partitioned cluster
Until few years back, most datacenter were statically partitioned. They were called statically partitioned because datacenter was a group of static clusters — Hadoop cluster, nginx cluster, and so on.
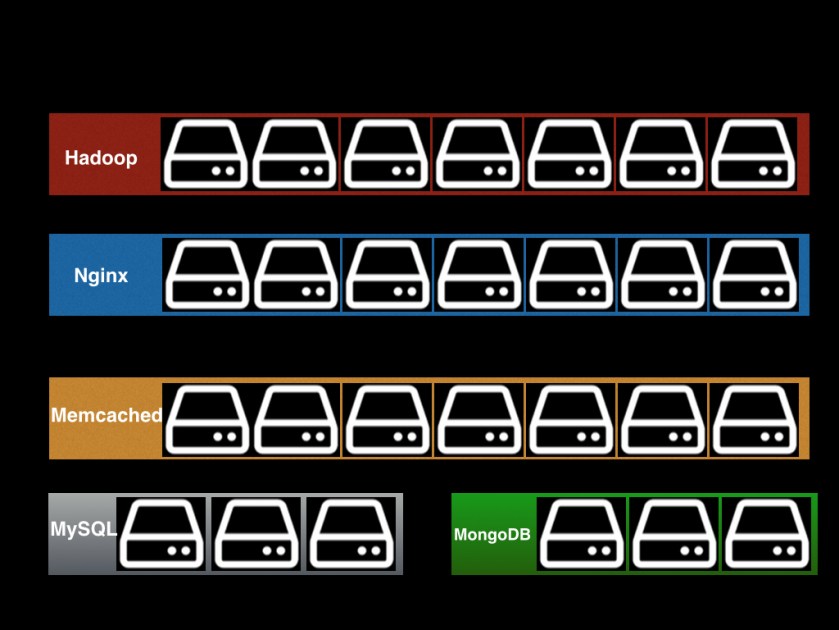
There are many limitations of traditional datacenter architecture. Some of these are mentioned below.
- Under utilization of resources
- Not possible to share resources across clusters
- No centralised view of entire datacenter
- Scale up leads to addition of more servers
The dynamically partitioned cluster
To overcome the limitations of statically partitioned cluster, research was done to build clusters that allow users to specify jobs in terms of resources they need and cluster will automatically run the application on a node that meets the resource requirement. One such system is Apache Mesos, an open source cluster manager that allows modern datacenter to function as a one large machine. It was started by Benjamin Hindman in 2009 along with his fellow PhD students at University of California, Berkeley. The goal was to create a software that will abstract CPU, memory, and disk resources in a way that allows modern datacenter to function like one large machine. It provides a unified API that allow users to work with the datacenter as a single pool of resources. Mesos was initially envisioned as open source version of Borg, a cluster manager that runs Google. Borg is considered to be one of the biggest secrets of Google. Google, in 2015 published a paper that talked about Borg.
In our knowledge, Mesos is the first main stream cluster management solution that showed us how to think and use a cluster of machines as a single machine. Mesos was initially geared towards virtual machines. As containers became mainstream, Mesos added first class support to run and manage containers.
Cluster management at Google with Borg
In 2015, Google published the Large-scale cluster management at Google with Borg paper. This paper goes in depth into the architecture of Borg and shares information on how Google internally uses it. Google Borg is considered to be a predecessor to Kubernetes, an open source software released in 2014 by Google for automating deployment, scaling, and management of containerised applications. Borg is considered to be one of the biggest cluster management solution. It runs most of the Google service including Gmail, Google Search, Google File System, and Google Compute Engine. Below is the image of high level architecture of Google’s Borg taken from the paper itself.

The main components are described below:
- Cell is a set of machines are managed as a single unit.
- Job defines a set of tasks that do the same thing. Job has a name, owner, and number of tasks to run. Job allows you to group identical tasks.
- Task is a linux process that does the actual work. They can also define their resource requirements.
- BorgMaster handles the client request and manages all the objects in the system.
- Slave is the worker machine that performs the task.
- Scheduler makes the actual decision of assigning which machine should run the task if there are sufficient available resources on the machine to meet job requirement.
- Borglet is an agent that runs on each machine in a cell that is responsible for starting, stopping, and restarting tasks; share state of the machine with the Borgmaster.
A typical cluster manager
A typical cluster manager is composed of three main components — Resource Manager, Task Manager, Scheduler.
- Resource manager is responsible for keeping track of resources like memory, CPU, and storage that are available at any given time in the cluster.
- Task Manager is responsible for task execution lifecycle. It is implemented as a state machine.
- Scheduler is responsible for scheduling tasks for execution. Schedule is responsible for assigning tasks to nodes based on the resources required to execute the task.
The world of schedulers
The most important component of any cluster manager is Scheduler. The purpose of scheduler is to decide which task runs on which machine. A scheduler has to run a variety of different tasks. Tasks could be short running or long running, High CPU or Low CPU variant, different memory requirements, different reliability needs, latency sensitive jobs, background cron jobs, etc.
The role of scheduler is to identify the job and place it at the right place for execution. As discussed in the Omega: flexible, scalable schedulers for large compute clusters paper by Google, there are three main approaches to scheduling.
- Monolithic scheduler uses single scheduler to handle all kinds of workloads. They handle requests sequentially. The main problem with scheduler architectures are: 1) hard to diversify 2) code growth 3) scalability bottleneck.
- Two-level scheduler have a centralised resource manager that offers compute resources to multiple independent schedulers. This is the approach taken by Apache Mesos. Scheduler asks for resources from the resource manager and it receives response in the form of offers. These offers only contain available resources i.e. resources not currently in use. As different schedulers can make requests at the same time, resource manager offers a given resource to one scheduler framework at a time. Thus, avoiding conflict. As mentioned in the Omega paper,
Because only one framework is examining a resource at a time, it effectively holds a lock on that resource for the duration of a scheduling decision. In other words, concurrency control is pessimistic.
The main problem with this approach is that scheduler frameworks does not have access to overall site of the cluster. This means using this approach you cannot support preemption or policies requiring access to the whole cluster.
- Shared-state optimistic scheduler is built around idea of shared state and lock-free optimistic concurrency control. Each scheduler maintains in-memory local copy of the overall cluster state. Schedulers make decisions based on their local state. This scheduling approach allows multiple schedulers to compete for resources. It relies on optimistic concurrency control to handle conflicts when schedulers try to update the cluster state. As mentioned in the Omega paper,
Once a scheduler makes a placement decision, it updates the shared copy of cell state in an atomic commit. At most one such commit will succeed in the case of conflict: effectively, the time from state synchronisation to the commit attempt is a transaction.
Amazon ECS
Now that we understand different scheduling approaches the description of Amazon ECS should make more sense. As per the Amazon ECS documentation,
Amazon EC2 Container Service (Amazon ECS) is a shared state, optimistic concurrency system that provides flexible scheduling capabilities for your tasks and containers.
Amazon ECS allows you to run applications on a managed cluster of Amazon EC2 instances. It take cares of two important functions 1) reliable state management 2) flexible scheduling. The state management is done using Paxos based transactional data store that keeps a record of every change made to a data entry. Paxos is a consensus based algorithm for agreeing on state within a distributed system. ECS allows you to use multiple schedulers at the same time. ECS offers two schedulers: task scheduler and service scheduler. You can also create your own custom schedulers that meet the need of your business or to use third party schedulers.
Amazon ECS like any managed EC2 service makes cluster management look an easy task. ECS takes care of all the challenges in running a distributed system. It take care of resource management and scheduling so that you can focus on building your application. ECS is designed to be highly scalable and available.
Conclusion
In this post, we covered the modern cluster managers and how different scheduling approaches differ. In the next post, we will start learning about Amazon ECS terminology and how you can use it.
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.
