I have started using gRPC for service to service communication between Microservices and I am liking it so far.
I still prefer to expose APIs to the external world(browser, mobile, or third-party) using either REST or GraphQL. I am aware that you can use gRPC in Mobile apps and you can use grpc-web in web frontends. But, I have not used gRPC for those use cases yet.
I have earlier used REST(JSON over Http) and/or some form of Event-driven communication for service to service communication. They both work but the programming model leaves much to be desired.
gRPC is a HTTP/2 based modern and efficient inter-process communication style developed by Google. It is heavily used at Google and many other major tech companies such as Square, Lyft, Netflix, CockroachLabs, Salesforce, and many others.
As shown in the picture below gRPC builds on top of HTTP/2 and SSL as the efficient and secure transport layer. It uses Protocol Buffer for defining API contracts and efficient serialization. gRPC core provides the framework to do efficient service to service communication. gRPC tooling generates clients and servers that are used by the application tier.
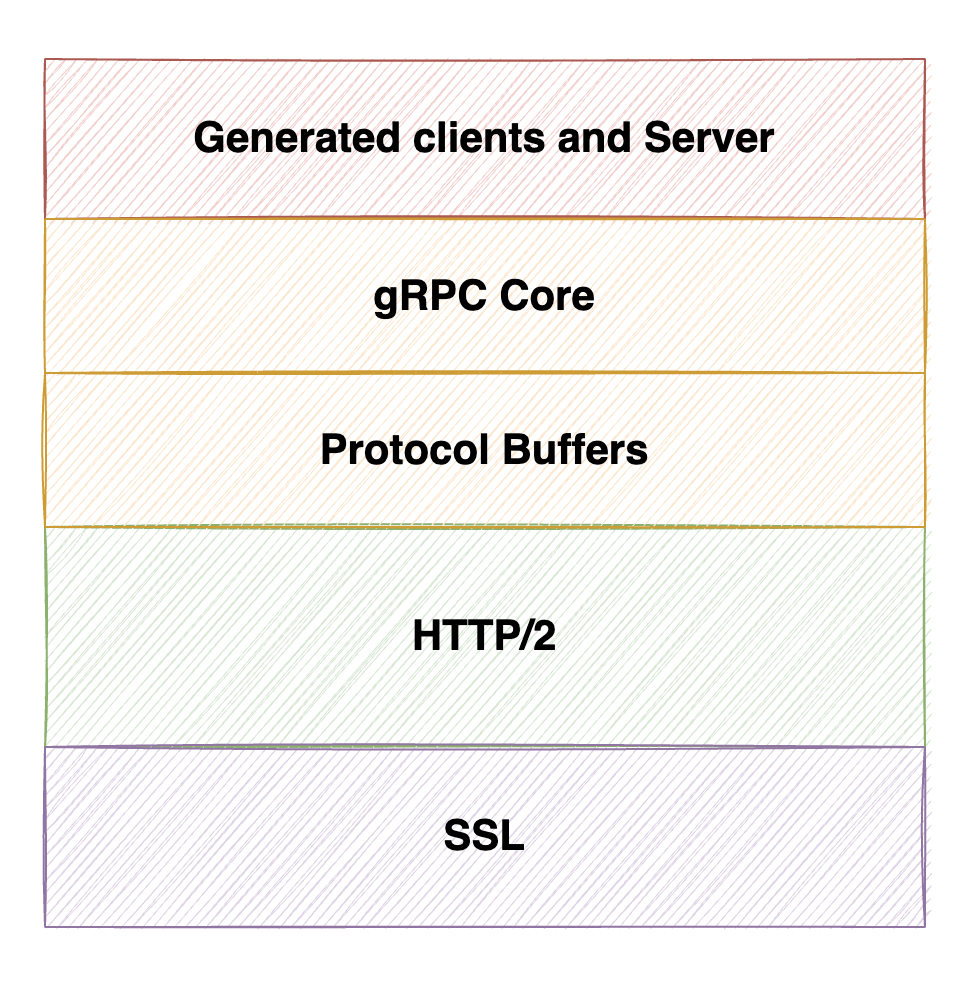
Now that we understand gRPC basics I will share my reasons to prefer gRPC for service to service communication.
Reason #1. Proto Interface Definition Language (IDL) is a natural way to do contract first development
I have long tried to do contract first API development in the REST world but OpenAPI/Swagger never felt natural during the design phase. You need a proper editor, remember YAML or JSON OpenAPI syntax, and repeatedly fight with YAML.
YAML or JSON is not the way I think about APIs. When I am designing APIs I think in a more free form manner.
YAML or JSON are the formats that I would prefer to generate rather than write myself. I think this is one reason engineering teams prefer to write code first and then generate OpenAPI specification from it.
Let’s take an example where we have to define an API to create a Todo item. When I design such an API I think in the format shown below.
POST /todos
TodoRequest {
title required string,
done optional boolean = false
}
TodoResponse {
id: int,
title: string,
done: boolean,
created_at: timestamp
}
ErrorResponse {
code int,
message string
}
Possible Errors:
1001 Bad request
1002 Duplicate title
5000 Server errorI can write a tool that can take my API format and convert it to the OpenAPI specification but that adds friction and I need to maintain it.
gRPC has a similar feel to the way I designed the above API. They call it IDL i.e. Interface Definition Language. I will create todo_api.proto as shown below.
syntax = "proto3";
package todo;
import "google/protobuf/timestamp.proto";
service Todo {
rpc createTodo(TodoRequest) returns (TodoResponse);
rpc getTodo(TodoId) returns (TodoResponse);
}
message TodoRequest {
required string title = 1;
optional done bool = 2;
}
message TodoResponse {
int32 id = 1;
string title = 2;
done bool = 3;
google.protobuf.Timestamp created_at = 4;
}
message TodoId {
required int32 value = 1;
}I find gRPC way to define service contracts more productive and intuitive. I can quickly create service endpoints and share it with my teams without going through the painful step of converting my API mental model to the OpenAPI syntax. For us it enables parallel development of the client and server side of our APIs with minimal effort.
The only thing missing in the above API contract is error responses. The error responses are not part of the API contract but they are part of the programmatic model. If an error occurs, gRPC returns error code along with an optional error message. You can return custom error objects as well.
The best part of gRPC is that the contract-first is the only way to develop APIs in it. You first define a strongly typed service interface and then you write any implementation code. The service interface as shown above includes operations and types used for communication between the components. This gives developers a consistent and stable development experience.
The use of statically typed strong service contract leads to better collaboration between the teams and minimal integration issues when you build apps that span across multiple teams and technologies.
Another benefit I experienced creating services using gRPC is that I don’t have to waste mental cycles coming up with correct RESTful APIs. Doing REST APIs right is a lot of work. You have to think which HTTP method to use, which HTTP error code to return, how to map operations other than CRUD in a RESTful manner, path variable vs query parameter, etc. REST makes HTTP visible in your API contract. It is a resource based design. gRPC on other hand is a functional design. You think about verbs more than nouns.
Contract first development using Event-driven style is still in its nascent stages. I am aware of the AsyncAPI specification and the work that the community is doing to build tooling around it. I don’t like that they have also standardized on YAML as the API specification language format. I have not used it in any real work yet so I am yet to form any opinions on it.
Reason #2. Code generation and tooling
To do contract-first API design in a productive manner you need to have the tooling that supports this API design style. Tooling can’t be a second class citizen or an afterthought. It has to be part of the developer workflow and ensure a standard and consistent way to define and create services.
The gRPC tooling supports contract-first paradigm and works with you rather than against you.
Code generation works on top of the Protobuf service contract. Code generation tooling in gRPC helps create client-side network stubs and server-side skeletons from the protobuf IDL. This means less development effort, reduced maintenance and making fewer decisions. I have wasted time deciding which HTTP client library to use to build clients for my REST APIs. Then, we have to maintain these clients for each language we support and publish them to a registry.
There are many other tools created by the gRPC community that can do linting of Protobuf service contracts, run benchmarks on gRPC services, do GUI based testing like Postman, and many others. You can find tools in awesome-grpc Github repository.
Reason #3. Baked in resiliency and distributed systems primitives
gRPC comes packaged with features like deadlines, timeouts, retries, cancellation, load balancing, and service discovery, tracing, metrics, and few others. It also supports other important features like authentication, encryption, compression, and so on. It also supports adding custom extensions via writing custom interceptors. You can write custom interceptors at both client and server side.
In this post I will only cover my favorite feature of Deadlines. Most of us have used timeouts in service clients. Timeouts allow you to specify how long clients should wait for an API call to complete before it terminates the call with an error. For example, if you have three services – A, B, and C where A calls B and B calls C. Then, you will have timeouts at service invocation i.e A and B. Timeouts do not span across the complete lifecycle of the request. Deadlines help solve this problem.
Deadlines are defined at the beginning of the request and are carried forward to all the downstream service invocations. The service that initiates the request sets the deadline and the entire call graph needs to execute within the deadline duration. Deadlines allow gRPC clients to specify how long they are willing to wait for an RPC to complete before the RPC is terminated with the error DEADLINE_EXCEEDED. By default this deadline is a very large number, dependent on the language implementation.
It is always a best practice to use deadlines as when you don’t set a deadline, resources will be held for all in-flight requests, and all requests can potentially reach the maximum timeout. This puts the service at risk of running out of resources, like memory, which would increase the latency of the service, or could crash the entire process in the worst case.
If you use gRPC in a mobile frontend then you can set a deadline for end to end request lifetime.
The Dropbox team also shared their usage of deadlines
In practice, we have fixed whole classes of reliability problems by forcing engineers to define deadlines in their service definitions.
This context can travel even outside of the RPC layer! For example, our legacy MySQL ORM serializes the RPC context along with the deadline into a comment in the SQL query. Our SQLProxy can parse these comments and KILL queries when the deadline is exceeded. As a side benefit, we have per-request attribution when debugging database queries.
Another related topic is cancellation. This ensures wasteful work is not done by the server when the request is canceled. When either the client or server wants to terminate the RPC this can be done by canceling the RPC. Once the RPC is canceled, no further RPC-related messaging can be done and the fact that one party has canceled the RPC is propagated to the other side.
One interesting feature in gRPC is multiplexing. It allows you run multiple gRPC services on a single gRPC server. It also works on the client side where connection is shared between multiple clients. This feature gives you a way to support multiple versions of the same service. You can follow the expand and contract refactoring using this feature.
gRPC supports three types of load balancing strategies
- Server-side:
- Needs Intelligent Proxy
- Clients can remain dumb
- Adds an extra network hop
- Client side:
- Requires no proxy at the server
- You have to write complex client
- You can achieve low latency as no extra network hop is required
- Lookaside :
- This also does not require proxy
- You can have a thinner client with some intelligence provided by the lookaside
- You can still achieve low latency as no extra network hop is required
Reason #4. Efficiency and Performance
gRPC helps you write efficient and performant services. This is achieved via following
- Connection reuse. gRPC uses HTTP/2 as the transport layer. HTTP/2 enables efficient use of network resources and reduces latency by using header field compression and allowing concurrency exchange in the same connection. On the other hand, when you use a REST call between the services a new connection is established with the overhead of SSL handshake.
- ProtoBuf on HTTP/2. gRPC uses a binary buffer-based protocol to communicate between services. Since gRPC uses protobufs on top of HTTP/2 it is more efficient and performant.
- Compression. Using gRPC compression on the client side can be implemented by setting a compressor when you do the RPC.
- Reduced network latency. gRPC builds on HTTP/2, which allows for faster and long-lived connections, reducing the time for setup/teardown common for individual HTTP/1.x requests.
According to tests published by Ruwan Fernando, gRPC API connections are considerably faster than REST API connections. In fact, he reported that they are 7 to 10 times faster
Reason #5. Supports multiple communication patterns
gRPC supports not one but four communication patterns.
- Simple RPC (Unary RPC). It is ubiquitous request/response synchronous model
- Server-Streaming RPC. In this pattern the server returns a stream of messages to the client request.
- Client-Streaming RPC.In this client sends a stream of messages to the server instead of a single message. Server responds with a single message.
- Bidirectional-Streaming RPC. In this client and server can read and write messages in any order once the client initiates the call.
- gRPC takes advantage of HTTP/2’s bi-directional communication support, removing the need to separately support request/response alongside websockets, SSE, or other push-based approaches on top of HTTP/1.
Conclusion
gRPC provides good development experience and features for service to service communication between Microservices. I will write a detailed post on how I am using it one my applications in a future post.
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.
