Today, I was working on an application that required me to extract the main content html for a web page. This is called article extraction. Most of the time you want to extract the text of the article but I wanted to extract HTML of the main content. For example, if you are reading following WashingtonPost article then I want to extract the main HTML content on the left. I don’t want sidebar HTML containing ads or other information.
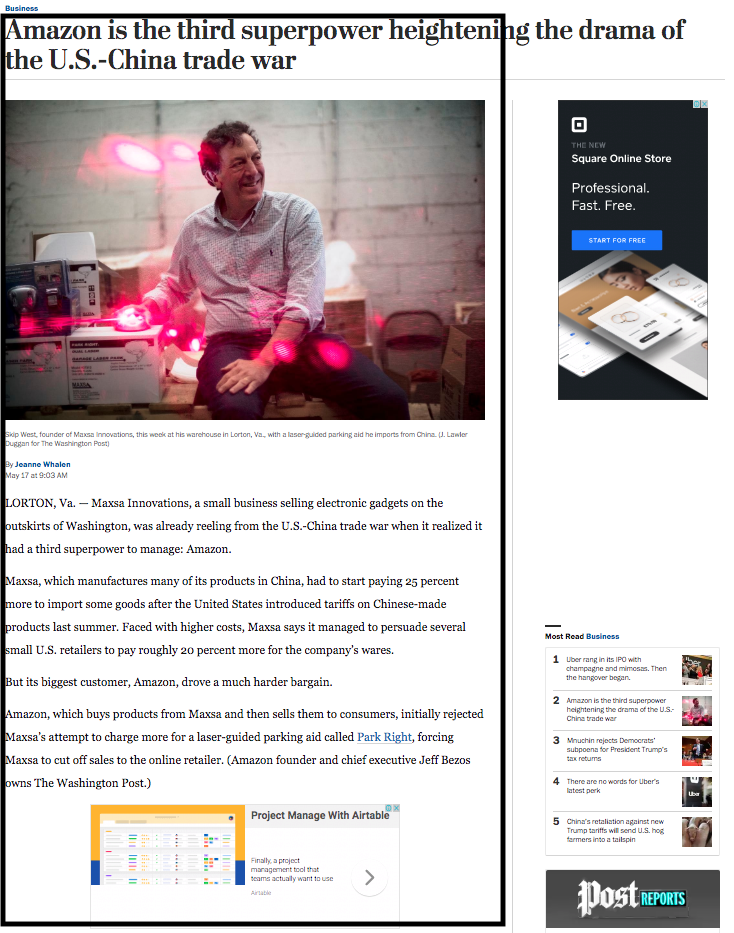
In this post, I will cover how to article extraction API with newspaper3k and flask framework.
Step 1: Create Python 3.7 virtualenv
To use Flair you need Python 3.7. We will start by creating a Python 3.7 virtualenv
$ python3.7 -m venv venv
Next, we activate the virtualenv
$ source venv/bin/activate
Next, you can check Python version
(pyeth) $ python --version
Python 3.7.2
Step 2: Install newspaper3k and flask package
To install newspaper3k and flask we will use pip as shown below
$ pip install newspaper3k flask
The above command will install all the required packages needed to build our API.
Step 3: Create a REST API to analyse sentiments
Create a new file called app.py under the application directory.
$ touch app.py
Copy the following source code and paste it in app.py source file
from flask import Flask, jsonify, request
from newspaper import Article, Config
import lxml
from html import unescape
app = Flask(__name__)
@app.route('/api/v1/extract', methods=['POST'])
def extract_html():
print("Inside extract")
print(request)
if not request.json or not 'articleUrl' in request.json:
abort(400)
article_url = request.json['articleUrl']
article_html = extract_article_html(article_url)
response = {'articleHtml': article_html}
return jsonify(response), 200
def extract_article_html(url):
config = Config()
config.keep_article_html = True
article = Article(url, config=config)
article.download()
article.parse()
article_html = article.article_html
html = lxml.html.fromstring(article_html)
for tag in html.xpath('//*[@class]'):
tag.attrib.pop('class')
return lxml.html.tostring(html).decode('utf-8')
The code shown above does the following:
- It imports Flask classes and functions
- Next, we import
ArticleandConfigclasses fromnewsppater3klibrary - Next, we defined a POST route mapping to
/api/v1/extracturl. This API endpoint will receive the article URL in a JSON body. We extracted the HTML of the main content using the newspaper3k Article class. We passed configuration option to keep article HTML in the Article object. If you don’t pass this configuration option thenarticle_htmlwill be empty. - Finally, we transformed the HTML by removing
classattribute from all HTML elements.
You can now start the app using flask run
Once application is started, you can test the REST API using on your favourite REST client. I will show how to make REST API using cURL.
The cURL request will extract article HTML for the WashingtonPost article we mentioned previously.
curl --request POST \
--url http://localhost:5000/api/v1/extract \
--header 'content-type: application/json' \
--data '{
"articleUrl": "https://www.washingtonpost.com/business/economy/amazon-is-the-third-superpower-heightening-the-drama-of-the-us-china-trade-war/2019/05/17/3b274486-7720-11e9-b7ae-390de4259661_story.html"
}'
The response returned by API is show below. I have trimmed part of the response for brevity.
{"articleHtml":"<div> <a name="TSPH2VDXIUI6TJ57ZCSDXBHOGE"></a> <img src="https://www.washingtonpost.com/resizer/6Od5ZEDxcon7zfINi8bRKAaRvbA=/1484x0/arc-anglerfish-washpost-prod-washpost.s3.amazonaws.com/public/TSPH2VDXIUI6TJ57ZCSDXBHOGE.jpg"><br> <p>Skip West, founder of Maxsa Innovations, this week at his warehouse in Lorton, Va., with a laser-guided parking aid he imports from China. (J. Lawler Duggan for The Washington Post)</p> <p> </p> <p> Maxsa Innovations, a small business selling electronic gadgets on the outskirts of Washington, was already reeling from the U.S.-China trade war when it realized it had a third superpower to manage: Amazon. </p> <p>Maxsa, which manufactures many of its products in China, had to start paying 25 percent more to import some goods after the United States introduced tariffs on Chinese-made products last summer. Faced with higher costs, Maxsa says it managed to persuade several small U.S. retailers to pay roughly 20 percent more for the company’s wares.</p> <p>But its biggest customer, Amazon, drove a much harder bargain.</p> <img src="https://www.washingtonpost.com/resizer/TXJKur-cQ3m4AF9lqk_kkjfemkk=/3x2/www.washingtonpost.com/pb/resources/img/spacer.gif"><br> <p>A warehouse in Lorton, Va., used by Maxsa Innovations. (J. Lawler Duggan for The Washington Post)</p> <p> </p> </div> "}
Step 4: Deploying It to Heroku
We can deploy our REST API to Heroku. First, we will install gunicorn library
pip install gunicorn
To do that, we will start by first freezing our dependencies to requirements.txt.
pip3 freeze > requirements.txt
This will create requirements.txt file in the root directory of your application.
Now, create a Procfile with following content that Heroku needs to know which command it should use to run the application.
web: gunicorn app:app
You wil have to make it a Git repository and add few files and directories to ignore.
$ git init
Create a .gitignore file
*.iml venv/ *.pyc .idea/ __pycache__ .vscode
Add and commit the source code.
$ git add --all $ git commit -am "First version of article-html-extractor service"
Once we have the requirements created, we will create a Heroku application.
$ heroku create article-html-extractor
You will have to use a different name. If you leave name empty then Heroku will create one for you.
Finally, you can deploy your service to Heroku by running following command.
git push heroku master
This will deploy the application.
You can again test the service using cURL as shown below.
curl --request POST \
--url https://article-html-extractor.herokuapp.com/api/v1/extract \
--header 'content-type: application/json' \
--data '{
"articleUrl": "https://www.washingtonpost.com/business/economy/amazon-is-the-third-superpower-heightening-the-drama-of-the-us-china-trade-war/2019/05/17/3b274486-7720-11e9-b7ae-390de4259661_story.html"
}'
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.
