A couple of weeks back a junior developer asked me a seemingly simple question – What is a distributed system? One question led to another and we end up spending more than an hour discussing different aspects of distributed systems. I felt my knowledge on distributed systems was rusty and I was unable to explain concepts in a simple and clear manner.
In the last two weeks since our discussion I spent time reading distributed systems literature to gain better understanding of the basics. In a series of post starting today, I will cover distributed system basics. In today’s post we will cover what and why of distributed systems.
What is a distributed system?
Before we explain what is a distributed system, let’s look at a couple of examples.
A WordPress application running on a single machine is an example of non-distributed system. A running WordPress will have following:
- Apache process serving the WordPress PHP back-end code
- MySQL database that WordPress use for data storage and retrieval
A scalable WordPress instance is an example of distributed system. A scaleable WordPress instance will be composed of following:
- Multiple Apache instances running on different machines serving the WordPress PHP back-end code
- A load balancer distributing load between different Apache instances
- MySQL cluster with master slave replication
- Memcached cache cluster
The above two examples can help us define characteristics of the two systems.
A non-distributed system is the one that:
- Runs all the components of the system on a single machine
- Limited by resources on a single machine
- Will loose or corrupt data if machine running the system breaks
- Fails to serve user requests if machine goes down
A distributed system is the one that:
- Runs components on separate machines
- Has redundancy at all layers. We run multiple copies of every component on different machines
- Replicates data so that single machine failure does not cause lose of data
- Continues to work even when one of the machines goes down. For example, if one of the Apache instances goes down application will still serve user requests.
- Gives the illusion that we have infinite resources
- Components talk to each other via message passing over the network
- Builds on top of other distributed systems (recursion illustrated!). In the above example it is true but if you are building a new distributed database then you might not have the luxury of building on top of an existing lower level distributed system.
In the paper A brief introduction to distributed systems[1], Maarten and Andrew defined distributed system as following
A distributed system is a collection of autonomous computing elements that appears to its users as a single coherent system.
The two key points in the above definition are:
- A collection of autonomous computing elements
- Single coherent system
Let’s get deeper into each of the two phrases.
A collection of autonomous computing elements
The first thing that becomes clear from the use of collection in this phrase is that we are talking about multiple computing elements. In their paper, authors defined computing element as either a hardware device or software process.
If we don’t consider the word autonomous in this phrase we can say that an application composed of multiple software process is a distributed system. So, both the examples defined above are distributed systems.
But, in my opinion the use of word autonomous makes things a bit different. One thing to keep in mind is that autonomous does not mean independent. To better understand difference between the two words I did a web search.
Autonomous means self-directed i.e. drive to act comes from inside yourself
Independent means not dependent on others.
Examples
- The child is able to play autonomously – she makes up her own games.
- The child is able to play independently – without her parents’ supervision.
In the WordPress example, Apache needs to talk to MySQL or Cache to get the job done. So, compute elements are not completely independent of each other. They work together to achieve a goal.
The question that we need to answer is does two or processes running on a single machine be considered autonomous?
In my view, two or more processes running on a single machine can’t be considered autonomous for two reasons:
- All processes will go down if machine crashes. Process lifecycle in some way is dependent.
- One process can make another process unresponsive or crash. If one process fills the entire disk space then the second process will fail to work.
Wikipedia[2] defines distributed systems as ones whose components are located on different network computers.
A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another. The components interact with one another in order to achieve a common goal.
My take is that distributed systems consists of multiple processes running on different machines connected via a network. There are papers published in academia like Your computer is already a distributed systems Why isn’t your OS? [3] that claims otherwise.
Single coherent system
The paper defines
A distributed system is coherent if it behaves according to the expectations of its users.
The end user should not be bothered on where different process are executing. They should not care if the data comes from replica 1 or replica 5. Also, it should not matter to them if replica 5 went down and replica 6 took its place.
Why we build distributed systems?
Distributed systems came into being out of necessity. There are four main reasons that force application developers to build distributed systems:
Scalability
Scalability can be defined as ease with which a system or component can be modified to fit the problem area in such a way that the system can accommodate increased usage, increased datasets, and remains maintainable.
There are two types scaling:
Vertical scaling : It is about adding more power to the single machine i.e. faster CPU , more RAM , SSD etc . Vertical scalability has a limit and the cost increases exponentially.
Horizontal scaling : It is about handling more requests and load by adding more machines. It requires special attention to application architecture.
A distributed system enabled you to build horizontally scalable systems.
Below is the image taken from book Building Scalable Web Sites by Cal Henderson which clearly shows that with vertical scaling cost increase exponentially whereas with horizontal scalability cost is linear.
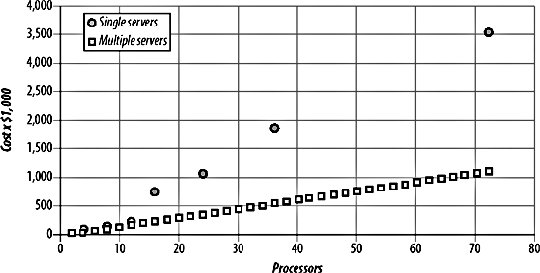
Horizontal scaling is the only way you can build applications that can scale to meet the needs of future.
Reliability and fault tolerance
The second main reason is to ensure that application can remain available to users when some node fails. With distributed systems, we add redundancy at each layer.
Performance
A single machine has finite resources that can handle only part of the load. When you put more load on the system than it can handle then system becomes slow and in worst cases die. We build distributed systems so that we can achieve low process the jobs with low latency.
Another reason related to performance is that we are limited by speed of light. If you have a user in New York making a request to server in Sydney then it will take minimum of 160ms. This means you can’t build a system that can perform faster then that. With distributed systems, we can put nodes in both geographies to allow user in NewYork to connect to node near to their location.
Content delivery network (CDN) are used to provide high availability and high performance by distributing the service spatially relative to end-users.
Uptime requirements
This goes hands-on in hand with reliability and fault tolerance. You can have tight uptime requirements and you can only meet them by building distributed systems.
References
- A brief introduction to distributed systems – Link
- Wikipedia page on distributed systems – Link
- Your computer is already a distributed systems Why isn’t your OS? – Link
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.

How would you differenetiate between microservices and distributed systems? Are they similar?
Hello Saket, Microservice architecture is one of the many ways to build distributed systems. Microservices are small, autonomous services that work together. This goes inline with definition of distributed systems by Maarten and Andrew
Can you pls create blog for kafka internal architecture?
NYC to Sydney is about 16,000 km and the speed of light is about 300,000 km/s. Information can travel from one city to the other in 53ms, not 160ms. Even a full round trip would be less than 160ms.