Today I was reading OpenAI guide on model selection https://platform.openai.com/docs/guides/model-selection where they explained how to calculate a reaslistic accuracy target for LLM task by evaluating financial impact of model decisions. They gave an example of fake news classifier.
In a fake news classification scenario:
- Correctly classified news: If the model classifies it correctly, it saves you the cost of a human reviewing it – let’s assume $50.
- Incorrectly classified news: If it falsely classifies a safe article or misses a fake news article, it may trigger a review process and possible complaint, which might cost us $300.
Our news classification example would need 85.8% accuracy to cover costs, so targeting 90% or more ensures an overall return on investment. Use these calculations to set an effective accuracy target based on your specific cost structures.
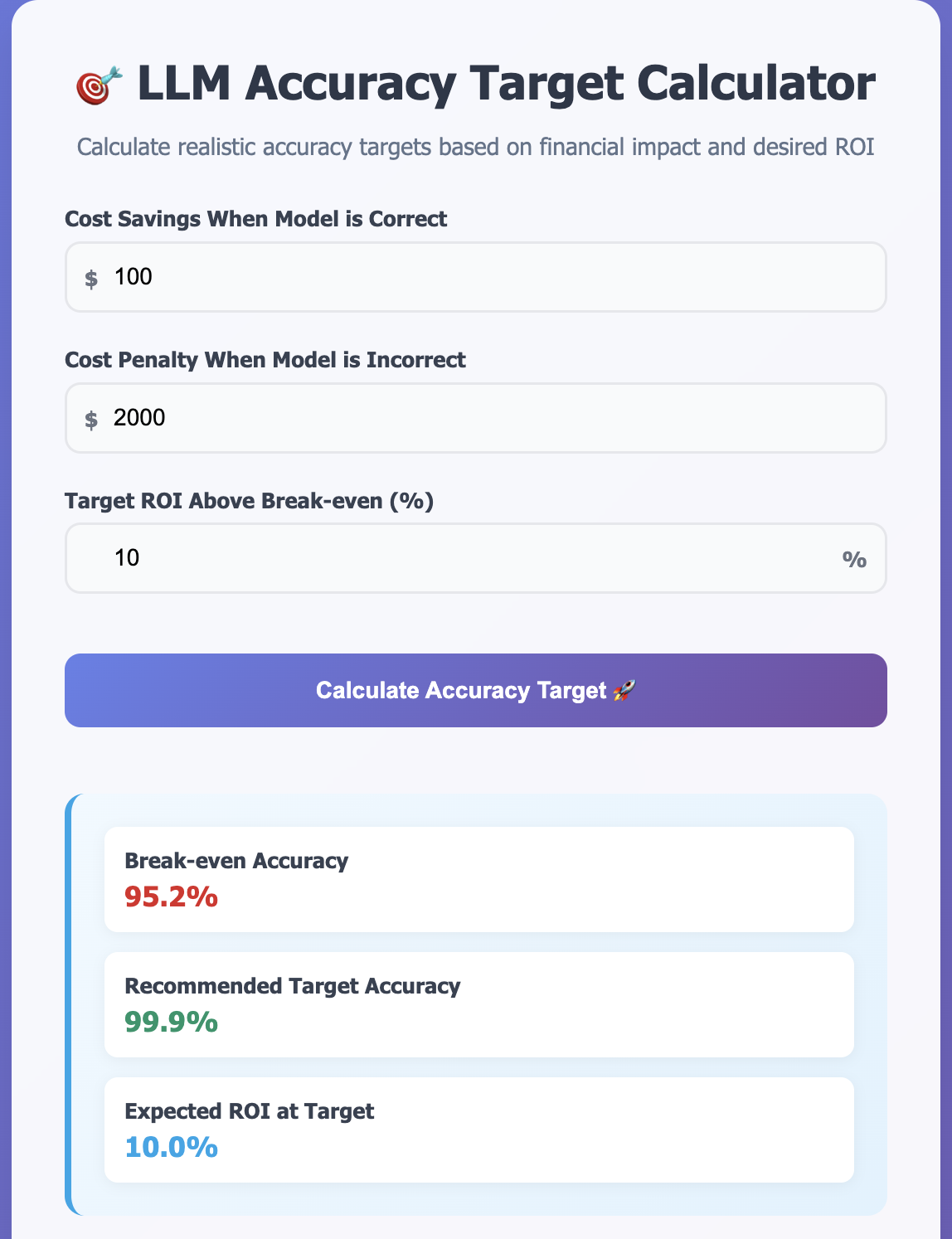
This is a good way to find the accuracy you need for the task. Break-even accuracy is calculated using the below formula
Break-even Accuracy = Cost of Wrong ÷ (Cost of Wrong + Cost Savings)
Below break-even you lose money. At break-even you break even. Above break-even you make profit. The target accuracy ensures your desired ROI. I have built a simple calculator that you can use https://tools.o14.ai/llm-task-accuracy-calculator.html.
This calculation works well when you are making binary decisions with LLMs. These are usually classification tasks. Below are some examples.
Content Moderation
- Correct: Properly moderate content → Save $20 in manual review
- Incorrect: Miss harmful content or over-moderate → $500 in legal/PR costs
Resume Screening
- Correct: Identify good candidate → Save $100 in recruiter time
- Incorrect: Miss good candidate or pass bad one → $2,000 in hiring costs
Code Review Automation
- Correct: Catch bug before production → Save $200 in developer time
- Incorrect: Miss critical bug → $10,000 in downtime costs
You can also adapt it to other domains like customer service chatbots. Instead of correct/incorrect, use quality tiers:
- High quality response: Save $25 (avoid human agent)
- Medium quality: $10 cost (requires follow-up)
- Poor quality: $75 cost (frustrated customer + human intervention)
Any LLM task with measurable business impact can use cost-benefit analysis – you just need to define what “quality” means for your specific use case and map it to financial outcomes.
