I was going over the code base of mini-swe-agent today. The core agent loop is 100 lines long. All agentic framework does something similar. Interesting facts about mini-swe-agent:
Only uses bash tool
Does not depend on function calling. It parses the response to extract commands that need to be run
The Mini-SWE-Agent operates in a continuous loop, iteratively solving problems by querying an LLM for actions, executing bash commands, and observing results until the task is complete.
In the last blog I discussed how I use OpenAI Code Interpreter to do RAG over data (CSV, Excel, etc.) files. OpenAI Code Interpreter is a managed offering and it does have some limitations. So, I was looking for an open source alternative. I discovered Pydantic team’s MCP Run Python package. It is an MCP server that allows agents to execute Python code in a secure, sandboxed environment. It uses Pyodide to run Python code in a JavaScript environment with Deno, isolating execution from the host system.
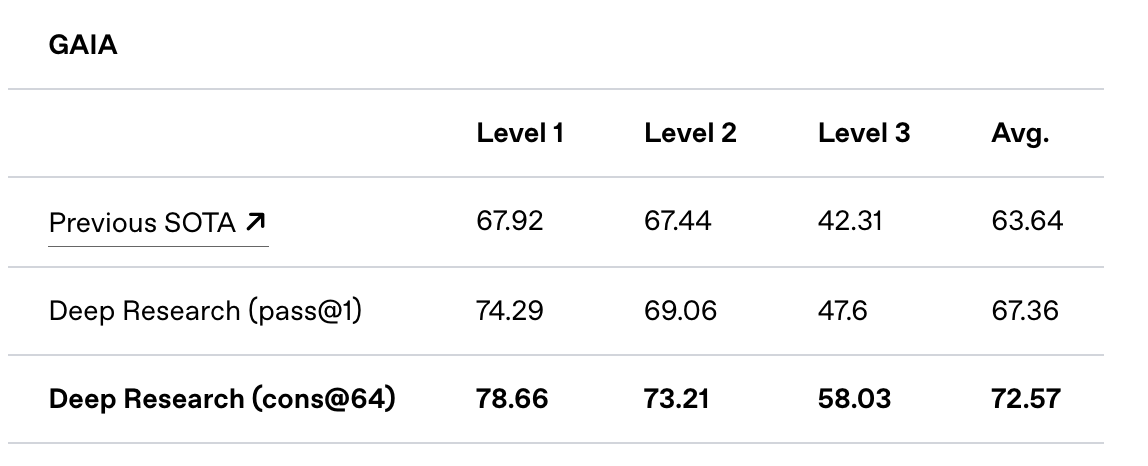
OpenAI recently released a new agentic application called Deep Research. This tool is available exclusively to pro users with a $200 monthly subscription. It utilizes their upcoming o3 reasoning model, which is not yet available via API. According to OpenAI’s blog, their Deep Research agent system achieves a score of 26.6% on the Humanity’s Last Exam evaluation benchmark. However, comparing an agent system directly to language models may not be the most appropriate comparison. A more suitable comparison would have been against similar research tools like Perplexity or Google’s Gemini Deep Research tool.
In addition to the Humanity’s Last Exam benchmark results, OpenAI shared their performance on the GAIA benchmark. GAIA is a public benchmark designed to evaluate AI systems on real-world questions, and the Deep Research agentic system has achieved a new state of the art (SOTA), leading the external leaderboard.
Today, HuggingFace launched an open source initiative to replicate OpenAI’s DeepResearch capabilities. It’s worth noting that while Google released their experimental Deep Research model in Gemini in December 2024, there weren’t any significant replication attempts at that time.
According to the HuggingFace team’s blog, they developed their prototype in under 24 hours and have improved upon the previous state of the art, advancing from Magentic-One’s 46% to 54% on the validation set.
I was surprised when I read that OpenAI o1 model does not seem to benefit agents. If a model can think and reason better than it should help agents make better decisions and be more reliable. In the CORE-Bench benchmark o1-mini scored 24% compared to 38% with Claude 3.5 Sonnet. The article cites two main reasons:
Inference scale models like o1 require different prompting styles than regular models, and current agentic systems are optimized for prompting regular models.
Reasoning or inference scale models so far have not been trained using reinforcement learning in a setting where they receive feedback from the environment — be it code execution, shell interaction, or web search. In other words, their tool use ability is no better than the underlying model before learning to reason.
Another reason I read is that o1 can sometimes behave strangely when integrated into custom agentic architectures, since it was trained to follow a specific reasoning process—indeed, OpenAI actively discourages users from using prompts that ask the model to reason in any specific way.