This is the video I recorded today that covers how I use Claude to build data annotation apps. I create data annotation apps for doing error analysis in my LLM apps. You can also view the video on Videocrawl – https://www.videocrawl.dev/studio?url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3Dz0Ktg0vLTBQ
Category: generative-ai
Google AI Overview Has a Timezone Bug
Yesterday (22nd March 2025), I used Google Search to check if ICICI Bank was open. I was planning to visit, but since banks are closed on some Saturdays in a month, I wanted to be sure before making the effort. I still rely on Google Search for tasks where I need to be 100% certain. Google provided the following response in its AI Overview:

At first glance, it looks like the correct answer. However, if you’re paying attention, you’ll realize that 22nd March 2025 is a Saturday, not a Friday. This means Google AI Overview provided the wrong answer. If you don’t double-check, you might assume it’s correct and waste a trip to the bank. Since I always verify AI-generated responses, I quickly spotted the mistake.
I asked the same question again today, and Google made the same error with the day. Additionally, it leaves the reader to figure out whether the date corresponds to the 2nd or 4th Saturday of the month. Ideally, an AI should provide a definitive answer.
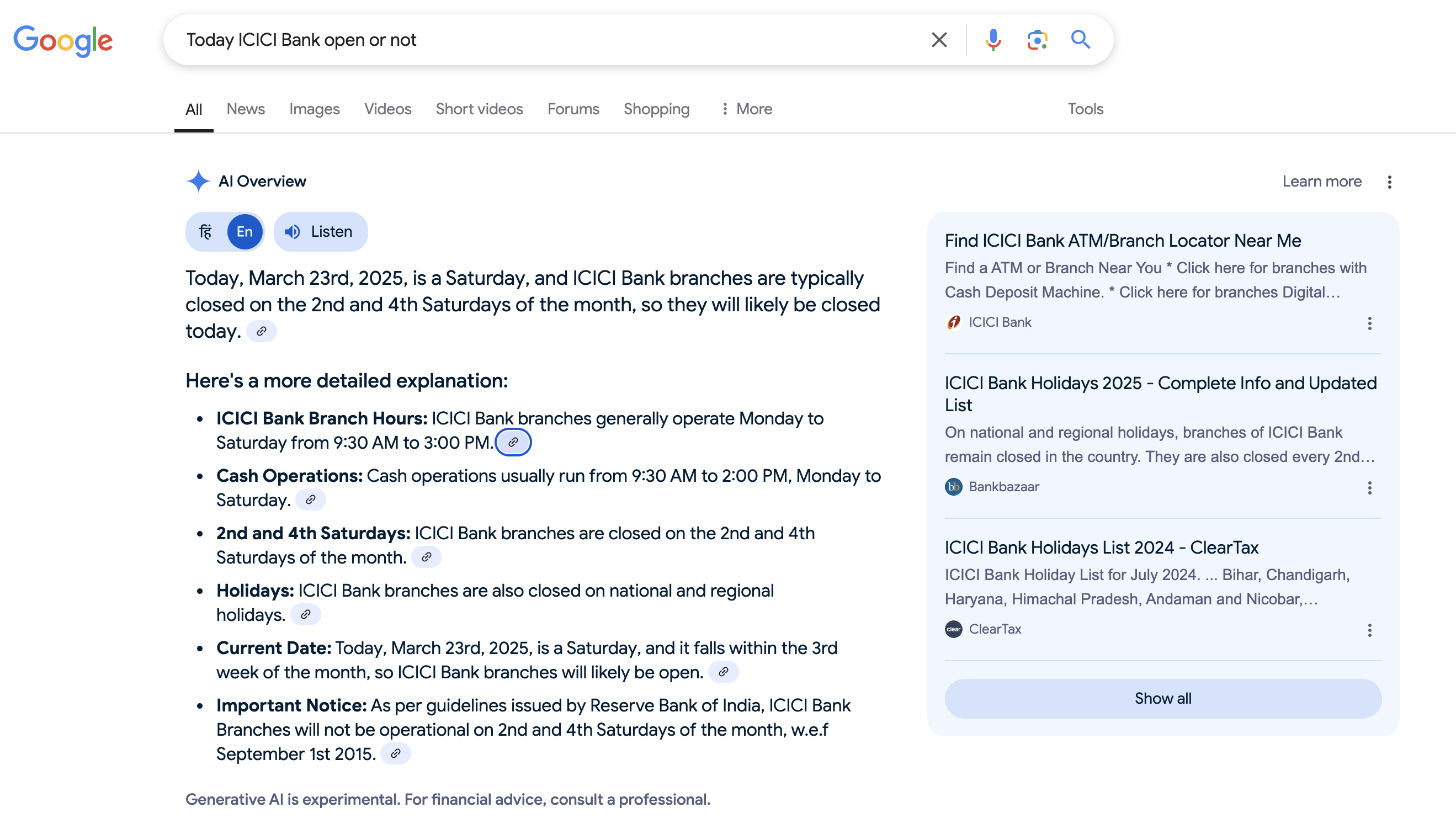
I also tried Gemini, but it merely summarized Google search results without directly answering the question: https://g.co/gemini/share/1290b734c69f
Next, I asked ChatGPT with search mode enabled. It correctly calculated the day but assumed I was in New Delhi, providing an answer relevant to that location. However, I actually live in Gurugram. The best part of ChatGPT’s response was that it informed me that one ICICI Bank branch in Gurugram remains open on Sundays. I wasn’t aware that some ICICI Bank branches operate 24/7—this was impressive.
You can view the full conversation here: https://chatgpt.com/share/67dfb367-fc98-800d-afed-53f66d672b2a
Perplexity also correctly stated that ICICI branches are closed on Sundays, but it lacked the level of detail provided by ChatGPT: https://www.perplexity.ai/search/today-icici-bank-open-or-not-GAjBqP67S2q9zD.OhU8Ihg
Timezone Issue in Google AI Overview
Most LLMs specify the current date in their system prompts. For example, Claude explicitly mentions the current date in its system prompt, ensuring accurate date calculations:
The assistant is Claude, created by Anthropic.
The current date is {{currentDateTime}}.
Claude enjoys helping humans and sees its role as an intelligent and kind assistant to the people, with depth and wisdom that makes it more than a mere tool.
This seems to be a timezone conversion issue. I am in the IST timezone, and both times I asked the question, it was before 12:30 PM IST. I assume Google’s servers operate in PST (which is 12 hours and 30 minutes behind IST). When converting the date to a day, they likely used the prior day instead.
I just asked the same question again at 1:15 PM IST, and now Google correctly shows that 23rd March 2025 is a Sunday.
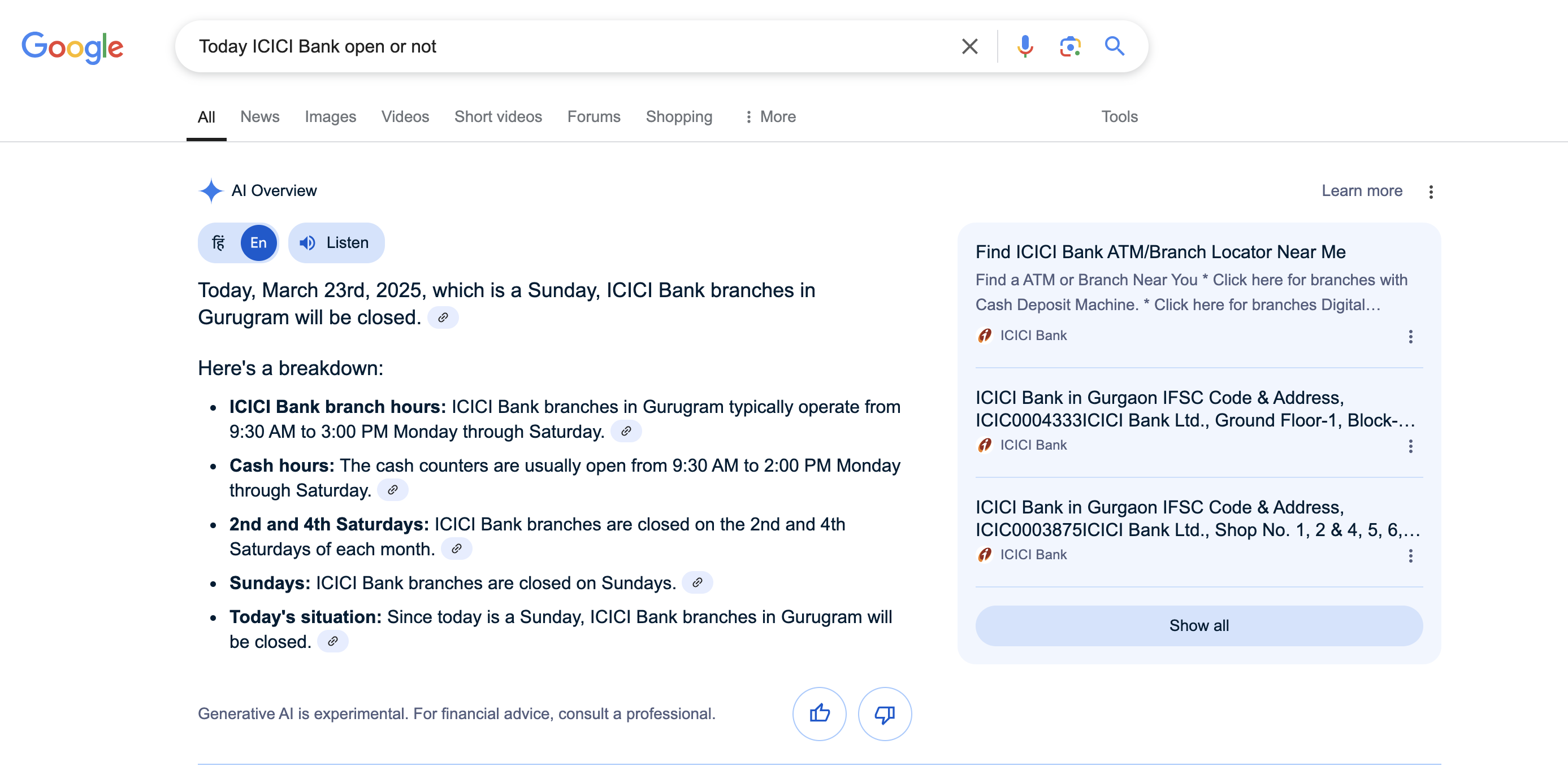
Before realizing that the issue resolves after 12:30 PM IST, I initially thought the AI was referring to outdated training data. Now, it all makes sense. It’s surprising that Google AI Overview has such a fundamental bug.
Lessons from How AI Breakout Harvey is Transforming Legal Services talk by Winston Weinberg
I watched an hour long talk by Winston Weinberg, co-founder and CEO of Harvey. Harvey is revolutionizing the legal industry through AI. They are one of the successful examples of LLMs in production. Following are the key points from the talk:
- The legal industry is particularly well-suited for large language models because it is text-based, and the value of a token is incredibly high. This could be a useful heuristic to see if your use case is a right fit for LLMs.
- I like how Winston described his product philosphy – Expand and Contract. The “expand and collapse” design philosophy refers to a strategic approach in product development, particularly in the context of creating workflows and user interfaces. This concept is about building specific, detailed workflows for complex tasks and then integrating them into a cohesive user experience.
- The focus on workflows to automate human work. The investment they are making in hiring domain experts and building repetitive workflows around them. Harvey collaborates closely with law firms to develop workflows that enhance efficiency and profitability, transitioning from a traditional seat-based model to one that also sells completed work.
- Business model evolving from seat based model to one of selling the work. More and more AI/LLMs starts up are offering co-workers which can autonomously get the work done.
- They targetted larger firms to establish their credibility. Their endorsement influence other firms and their clients.
I watch all videos on Videocrawl now as I can watch, read, chat, summarize, take notes etc all from the same web app. You can watch this video on Videocrawl by going to following link https://www.videocrawl.dev/studio?url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DeXK-_yyQDMM
If you are building LLM products I strongly recommend watching this talk.
Claude 3.7 Sonnet is good at PDF processing
I am working on a regulatory intelligence product. We are using LLMs in multiple document processing tasks. One of the tasks that I was working on today required me to extract text from a PDF document. The PDF in question is a circular from SAMA (The Saudi Central Bank). The 2-page long PDF is in Arabic language and looks like a natively digital document with consistent formatting rather than a scanned document.
The task that I wanted to perform was to extract the Arabic text and translate it to English. This looks like an easy task that most LLMs should be able to do since they all support PDF processing and they can read and write different languages.
Below is the screenshot of the first page of the document.

I tried four models on this PDF: gpt-4o via https://chatgpt.com/, Grok 3 via https://grok.com/, Gemini 2.0 Flash via https://gemini.google.com/, and Claude 3.7 Sonnet via https://claude.ai/. Below are my findings.
For all the models, I just uploaded the PDF and prompted Extract text as English.
Solving a Fifth Grade Puzzle with Latest Reasoning Models
My 10-year-old niece sent me a puzzle that she wanted me to solve. She has her general knowledge paper tomorrow and was unable to get the correct answer, so she asked if I could solve the puzzle. My wife and I both tried to solve it, and we got the same answer that my niece already had. The problem was that, according to her book, that answer was not correct. So, I thought I’d ask reasoning models to find the answer.
Below is the puzzle. We have to find the value for the question mark:
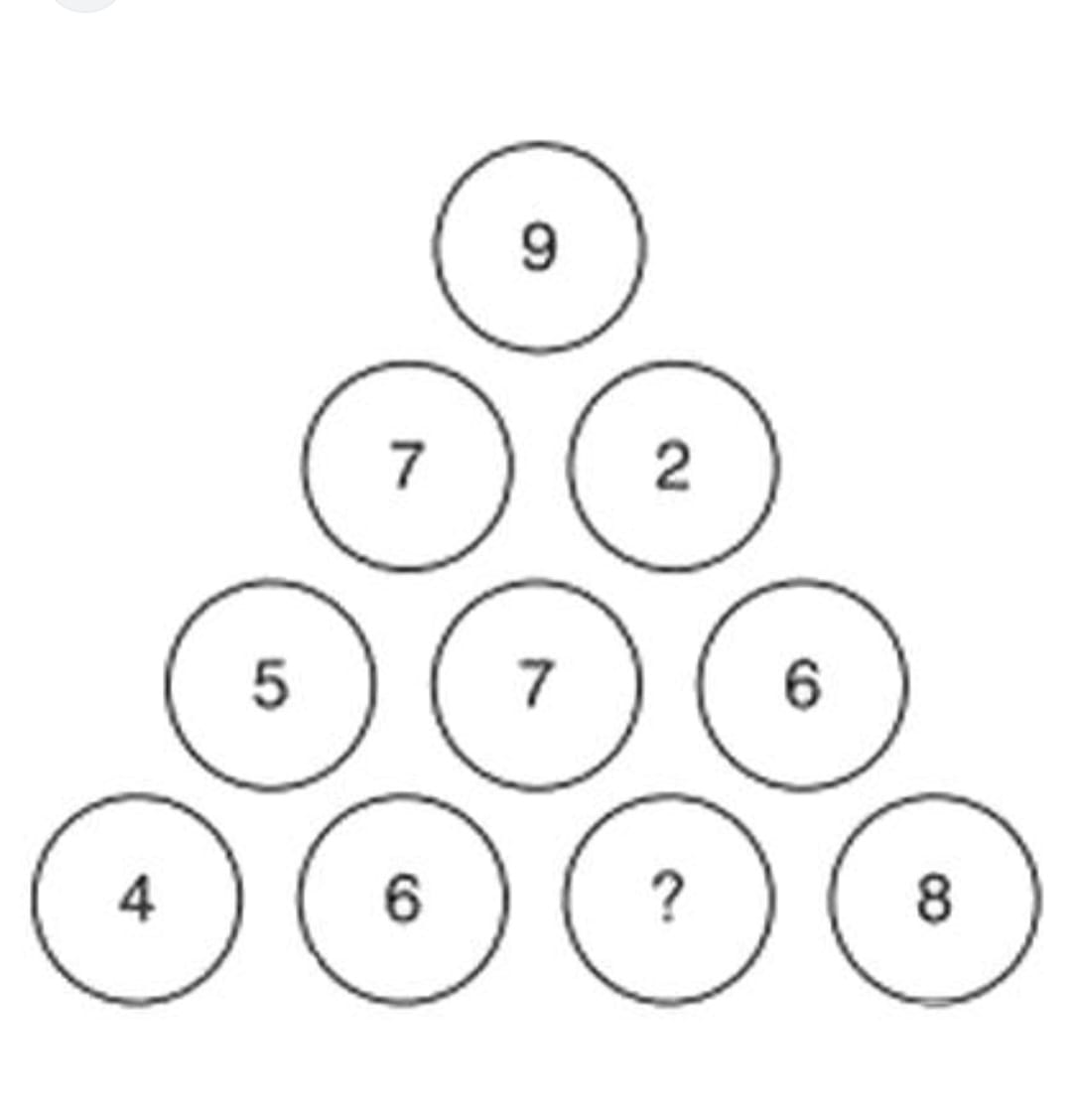
It is a simple number pattern puzzle. You have to identify which pattern this puzzle uses to find the number. My wife, my niece, and I all got 9 as the answer. My niece’s book suggested 7 as the answer. We just couldn’t figure out how to get 7. To us, it looks like a printing mistake in her book.
Below is what each of the models produced. I uploaded the image and prompted them to “Solve the puzzle.”
Continue reading “Solving a Fifth Grade Puzzle with Latest Reasoning Models”The Shape of Stories: Vonnegut-Inspired Analysis Tool with Claude 3.7 Sonnet
I was watching a video which introduced me to Kurt Vonnegut shapes of stories. Kurt Vonnegut believed that all stories have simples shapes. He proposed that stories can be categorized into basic shapes based on their emotional arcs. Below are eight example shapes he discussed in his work.
Continue reading “The Shape of Stories: Vonnegut-Inspired Analysis Tool with Claude 3.7 Sonnet”Can Claude 3.7 Sonnet generate SVG illustration for Maha Kumbh?
Anthropic released Claude 3.7 sonnet yesterday and I am liking vibes of it in my coding related tasks. Claude 3.7 Sonnet is a reasoning model like OpenAI o1/o3, Deepseek R1, Grok 3, and Google Gemini 2.0 Thinking.
I asked Claude 3.7 Sonnet to generate SVG visualization of Maha Kumbh. Kumbh Mela is an important Hindu pilgrimage, celebrated approximately every 6 or 12 years, correlated with the partial or full revolution of Jupiter. A ritual dip in the waters marks the festival.
I know we should use an image model but I wanted to see how far we can go with SVG with current reasoning models.
Below is the prompt
Generate an SVG illustration of the Maha Kumbh Mela, capturing its spiritual essence and vibrant atmosphere. The scene should include:
- Naga Sadhus (holy men) with ash-covered bodies and matted hair, some meditating and others engaging in rituals.
- Priests performing traditional Hindu ceremonies with sacred fire (yagna) and offering prayers.
- Devotees of various ages taking a holy dip in the river, expressing devotion and spiritual connection.
- People with folded hands praying to Lord Shiva, some with rudraksha beads and others offering milk or flowers.
- A grand backdrop of temple structures, flags, and colorful tents representing the spiritual congregation.
- Include iconic elements like tridents (trishul), damaru (drum), and Om symbols to reinforce the devotion to Lord Shiva.
Ensure the composition is detailed, with intricate line work and vibrant color contrasts to reflect the grandeur and sanctity of Maha Kumbh.
Below is the output of Claude 3.7 Sonnet with Extended Thinking. It thought for 4 seconds and generated below.

I also tried Grok3 as well. I had to tell it multiple times to generate SVG code. It defaulted to explanation with no code. After multiple tries this is what it generated.

Lastly, I tried OpenAI o3 mini. It generated following SVG.
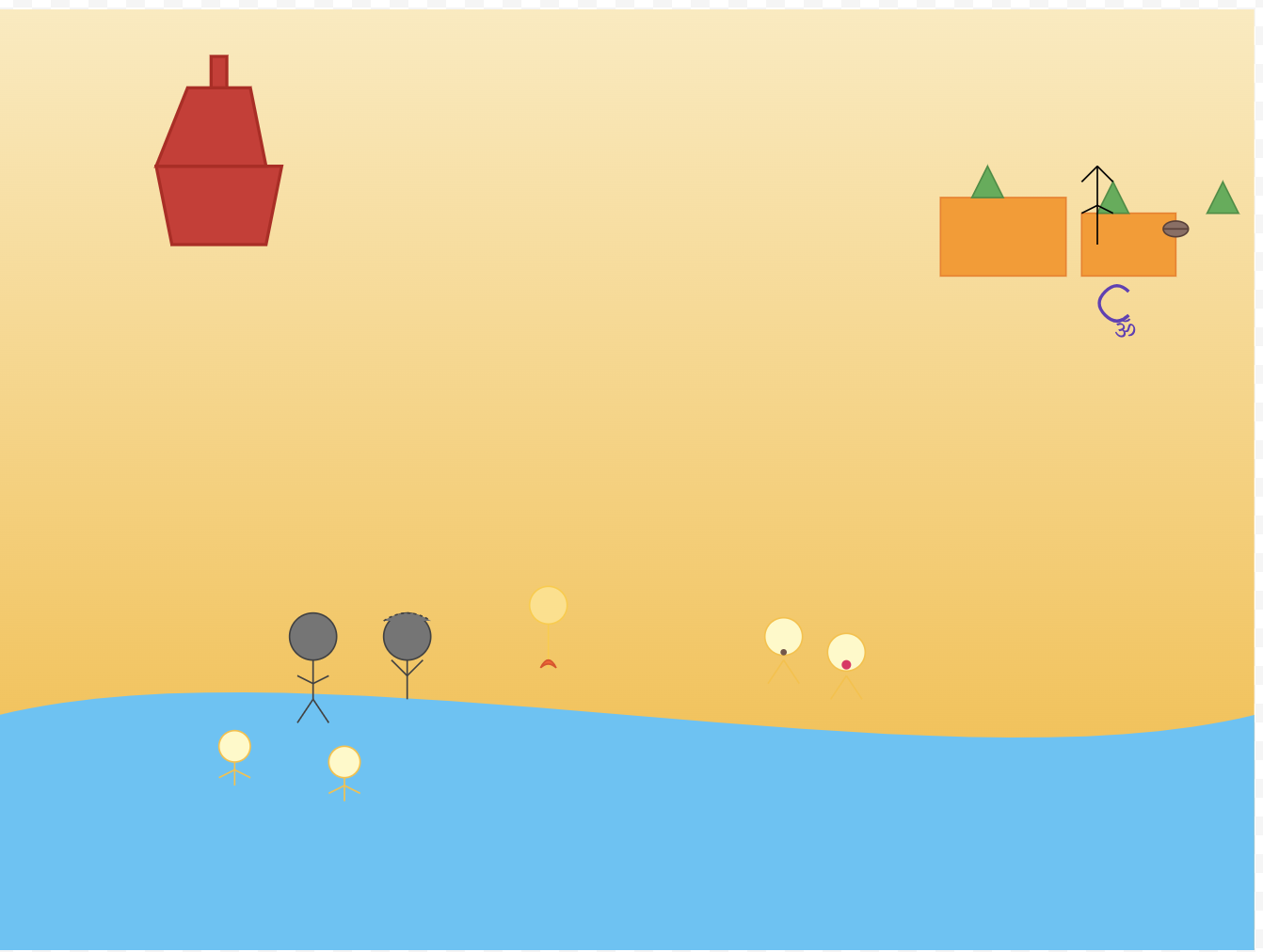
I liked Claude 3.7 Sonnet version. I think it captured few things well like Shivling.
Paper: Expect the Unexpected: FailSafe Long Context QA for Finance
I am always looking for practical, real-world papers that can help in my work. I provide AI and LLM-related consultancy to multiple clients, most of whom are in the financial domain. One of the first things I do as part of my consulting engagement is create test datasets that can help me baseline and improve AI systems. This usually requires spending time with business/domain folks and looking at/reading/analyzing a lot of data. Today, I stumbled upon a paper Expect the Unexpected: FailSafe Long Context QA for Finance that details how they created a realistic dataset specific to the financial domain. For each record in the dataset, they have introduced query and context perturbations and evaluated how different models perform. They have done benchmarking on both reasoning and non-reasoning models. The paper covers two main aspects:
- Testing how well LLMs handle real-world variations in queries and document quality when processing financial information
- Focusing on long-context scenarios (like 10-K reports) where accuracy is crucial
xAI Grok 3 is impressive
Yes, I remember that I posted a couple of days back that I was not impressed by Grok 3. Until then I didn’t have access to the model. I only saw the launch video by Elon and his team. For some reason I found the video too boring, scripted, and self-boasting that I decided to write off xAI Grok 3. Today, I saw on X that Grok 3 is freely available, so I decided to give it a try.
I am working on a problem where we have multiple Excel reports with different formats and we want to read all the tables in these Excel files in a generic manner. We can have one or more tables in an Excel sheet. I have tried two approaches before trying out the Grok 3 approach, and they worked to some extent.
Continue reading “xAI Grok 3 is impressive”My Thoughts on xAI Grok 3
Just wasted my 40 mins watching Grok 3 launch video. Below is what I posted on HN thread.
I don’t know, but I found the recording uninspiring. There was nothing new for me. We’ve all seen reasoning models by now—we know they work well for certain use cases. We’ve also seen “Deep Researchers,” so nothing new there either.
No matter what people say, they’re all just copying OpenAI. I’m not a huge fan of OpenAI, but I think they’re still the ones showing what can be done. Yes, xAI might have taken less time because of their huge cluster, but it’s not inspiring to me. Also, the dark room setup was depressing.
