In the last blog I discussed how I use OpenAI Code Interpreter to do RAG over data (CSV, Excel, etc.) files. OpenAI Code Interpreter is a managed offering and it does have some limitations. So, I was looking for an open source alternative. I discovered Pydantic team’s MCP Run Python package. It is an MCP server that allows agents to execute Python code in a secure, sandboxed environment. It uses Pyodide to run Python code in a JavaScript environment with Deno, isolating execution from the host system.
Continue reading “Using Pydantic MCP Run Python as an Open Source Alternative to OpenAI Code Interpreter”Category: generative-ai
Paper: AbsenceBench: Why Language Models Struggle to Detect Missing Information
While large language models (LLMs) have achieved remarkable capabilities in processing long contexts and locating specific information, a recent paper reveals a surprising blind spot: they struggle significantly when asked to identify what’s missing. The AbsenceBench paper by researchers from University of Chicago and Stanford University exposes a fundamental limitation that has far-reaching implications for how we evaluate and deploy these models.
The Problem: Detecting Absence vs. Presence
Large language models excel at the “Needle in a Haystack” (NIAH) test, where they successfully locate specific information buried within long documents. However, AbsenceBench introduces the inverse challenge: given an original document and a modified version with deliberately removed content, can models identify what’s missing?
The results are sobering. Even state-of-the-art models like Claude-3.7-Sonnet achieve only 69.6% F1-score with a modest average context length of 5K tokens. This represents a dramatic performance gap compared to their near-perfect performance on information retrieval tasks.
The Research Methodology
The researchers designed AbsenceBench across three distinct domains to test different types of missing information:
- Numerical sequences: Mathematical progressions with specific numbers removed
- Poetry: Excerpts from the Gutenberg Poetry Corpus with missing lines
- GitHub pull requests: Code diffs with deliberately omitted lines
The complete dataset is available on Hugging Face and contains 4,302 instances across all domains with an average context length of 5K tokens. You can easily load the dataset for experimentation:
from datasets import load_dataset
# Load specific domain
dataset = load_dataset("harveyfin/AbsenceBench", "poetry")
# Or load other domains: "sequences", "github_prs"
To demonstrate this limitation, below is a simple reproduction. You can view the complete implementation here.
from openai import OpenAI
client = OpenAI()
system_prompt = """You are helping a student practice memorizing poems.
The student will recite a poem, but they may have missed some lines.
Your task is to identify exactly which lines are missing from their recitation.
List only the missing lines, nothing else."""
user_message = f"""Here is the complete original poem:
{original_context}
Now, here is my recitation which may be missing some lines:
{modified_context}
What lines did I miss? Please list only the missing lines, nothing else."""
response = client.responses.create(
model="gpt-4-1-mini",
instructions=system_prompt,
input=user_message,
temperature=0
)
Striking Performance Results
The experimental results reveal the extent of this limitation. In one test with 72 lines deliberately removed from a document:
gpt-4.1-mini performance:
- Identified correctly: 37 missing lines
- Failed to identify: 35 missing lines
- False positives: 132 lines incorrectly flagged as missing
o4-mini performance:
- Identified correctly: 37 missing lines
- Failed to identify: 35 missing lines
- False positives: 6 lines incorrectly flagged as missing
While o4-mini significantly reduced false positives, both models still missed nearly half of the actual omissions, demonstrating that this isn’t simply a problem solved by more advanced reasoning capabilities.
The Attention Mechanism Hypothesis
The research suggests this poor performance stems from a fundamental limitation: Transformer attention mechanisms cannot easily attend to “gaps” in documents since these absences don’t correspond to any specific keys that can be attended to.
This insight is crucial for understanding why the problem exists. Traditional Transformer architecture excels at finding and attending to relevant information present in the input. However, when information is missing, there’s literally nothing for the attention mechanism to focus on—creating a fundamental blind spot in the model’s processing capabilities.
The Placeholder Solution
The researchers discovered a remarkable workaround: inserting placeholders where content is missing dramatically improves performance by 35.7% on average. This finding supports their hypothesis about attention mechanisms struggling with “gaps.” When placeholders provide something concrete to attend to, models can better identify the missing content.
This suggests that the issue isn’t necessarily about understanding absence conceptually, but rather about the architectural limitations of how Transformers process information gaps.
Real-World Implications
This limitation has serious implications for several critical applications:
LLM-as-a-Judge Systems: When AI models evaluate content, essays, or responses, their inability to detect missing information could lead to inflated scores and missed deficiencies.
Legal and Regulatory Analysis: As mentioned in the original research context, regulatory intelligence systems that compare document versions need to reliably identify what has been removed or changed between iterations.
Misinformation Detection: Detecting misinformation often requires identifying what key information is conspicuously absent from a claim or report.
Academic and Content Evaluation: Grading systems that rely on LLMs may fail to penalize incomplete responses appropriately.
Quality Assurance: Any system using LLMs to verify completeness of documentation, procedures, or reports faces inherent limitations.
A Broader Pattern of AI Limitations
The paper’s findings illuminate what researchers call the “jagged frontier” of AI capabilities—where models can be superhuman at one task while failing unexpectedly at a closely related one. As noted in recent analysis, “Long context models have been getting increasingly good at passing ‘Needle in a Haystack’ tests recently, but what about a problem in the opposite direction?”
This pattern suggests that current evaluation methods may be missing critical failure modes. The stark contrast between NIAH performance and AbsenceBench results highlights how misleading current evaluations might be if they ignore absence detection.
Future Directions
The research opens several important avenues for improvement:
Architecture Innovation: Developing attention mechanisms specifically designed to handle information gaps and absences.
Evaluation Framework Enhancement: Incorporating absence detection as a standard evaluation criterion alongside traditional benchmarks.
Training Methodology: Exploring ways to train models explicitly on absence detection tasks.
Placeholder Strategies: Investigating optimal approaches for using placeholders to improve absence detection in practical applications.
Conclusion
AbsenceBench reveals a fundamental blind spot in current language models that goes beyond simple performance metrics. The inability to reliably detect missing information represents a core limitation that could undermine trust in AI systems across numerous high-stakes applications.
Bottom line: While LLMs excel at finding needles in haystacks, they struggle significantly when the needle was never there to begin with. This limitation suggests we need both architectural innovations and more comprehensive evaluation frameworks that test for what models can’t see, not just what they can find.
As we continue to deploy these systems in critical applications, understanding and addressing this absence detection limitation becomes not just an interesting research problem, but a necessity for building truly reliable AI systems. The research provides a crucial foundation for developing more robust and trustworthy language models that can handle the full spectrum of information processing tasks—including recognizing when something important is missing.
Resources
- Paper: AbsenceBench: Language Models Can’t Tell What’s Missing (arXiv:2506.11440)
- Dataset: harveyfin/AbsenceBench on Hugging Face
- Code: GitHub repository with full implementation
- Quick demo: Gist with reproduction example
Use OpenAI Code Interpreter To RAG over user data
When building RAG systems, one common challenge is helping users query their own data. Users often come with a couple of Excel files, Word documents, or CSV files and want to ask questions like “Which department has the highest expenses?” or “What are the trends in our sales data?” Traditional RAG approaches struggle here because they’re designed for large, pre-processed knowledge bases, not for ad-hoc analysis of user-uploaded files.
I am a big fan of OpenAI’s Code Interpreter feature for solving exactly this problem. The code interpreter allows models to write and run Python code in a sandboxed environment to solve tasks. It is available in all tiers of ChatGPT, so you might already have seen it in action. Last week, I used it to process a huge (50 sheets) Excel file and extract a structured JSON from it. It first generated the code, then executed the code against my Excel file, and then gave me a link to download the JSON. The best part is that you can iterate over the solution in a step-by-step manner throughout the complete conversation.
If you have data in Excel, CSV, or any other structured format like JSON or XML, then you can use the code interpreter tool to ask questions about the data. For me, this is a better way to do RAG over user data when the data is not huge. Unlike traditional RAG that requires preprocessing, embedding, and vector storage, the Code Interpreter approach lets users directly upload their files and start querying immediately.
Continue reading “Use OpenAI Code Interpreter To RAG over user data”Reward Hacking
One term that I have been hearing a lot lately is reward hacking. I have heard this term multiple times from folks at OpenAI and Anthropic, and it represents a fundamental challenge in AI alignment and reliability.
What is Reward Hacking?
Reward hacking, also known as specification gaming, occurs when an AI optimizes an objective function—achieving the literal, formal specification of an objective—without actually achieving an outcome that the programmers intended. This phenomenon is closely related to Goodhart’s Law, which states “When a measure becomes a target, it ceases to be a good measure”.
The technical community distinguishes between several types of reward-related failures:
- Specification gaming: When the AI achieves the literal objective but not the intended spirit of the task
- Reward hacking: Finding unintended exploits in the reward function as implemented
- Reward tampering: Actively changing the reward mechanism itself
First impression of Mistral Devstral Model
Mistral released a new model yesterday. It is designed to excel at Agentic coding tasks meaning it can use tools. It is Apache 2.0 license. It is finetuned from Mistral-Small-3.1, therefore it has a long context window of up to 128k tokens. It is a 24B parameter model that uses Tekken tokenizer with a 131k vocabulary size. As per their release blog
Devstral achieves a score of 46.8% on SWE-Bench Verified, outperforming prior open-source SoTA models by more than 6% points. When evaluated under the same test scaffold (OpenHands, provided by All Hands AI 🙌), Devstral exceeds far larger models such as Deepseek-V3-0324 (671B) and Qwen3 232B-A22B.
If you have a machine with memory more than 32GB then you can run this model using Ollama
ollama run devstral:latest
I tried it on one of the use cases I am working on these days. The use case is generating Apache JEXL expressions. We extend JEXL with custom functions so in our prompt we also provide details of our parser. We also provide valid examples of JEXL expressions for model to do in-context learning. We are currently using gpt-4o-mini which has worked well for us.
I replaced it with devstral:latest via Ollama OpenAI compatible REST API and following are my findings:
- We found devstral latency high compared to gpt-4o-mini. It takes on average 1 minute to generate code. On the other hand gpt-4o-mini responds in less than 30 seconds.
- devstral does not follow instructions well. We explicitly instructed it to only generate code without any explanation but it still defaults to explanation. We had to add a post processing step to extract code blocks using regex
- For some expressions it generate SQL instead of JEXL expressions. In our prompt we have given a few shot examples of valid JEXL expressions but it still generated SQL.
- It failed to generate valid JEXL code when expression required using functions like
=~.It generated incorrect JEXL expressions
Mistral’s devstral failed to generate valid JEXL expressions. It might be better for more popular programming languages like Python or Javascript but for small languages like JEXL it failed to do a good job.
How We Used Claude to Implement Text Synchronization Feature of Videocrawl
At Videocrawl https://www.videocrawl.dev/, we’ve been exploring how AI assistants can enhance our development process. Recently, we built a text synchronization feature for our video player using Claude as our AI pair programmer. The feature highlights transcript text as a video plays, but the journey to get there revealed both the strengths and limitations of AI-assisted development.
The Initial Approach
We presented Claude with our requirements: synchronize transcript text with video playback, highlight the current text, and auto-scroll to keep it visible. Claude quickly generated a wireframe showing how the feature would look and proposed an initial implementation.
The first solution used custom HTML spans with direct styling to highlight words. While technically sound, this approach had a critical flaw: it broke our existing markdown rendering system. The highlighting was being applied at the DOM level after markdown processing, causing formatting inconsistencies.
As the developer, I had to intervene: “This breaks our markdown formatting. Can we use markdown bold tags instead of custom styling?”
Claude immediately pivoted to a new approach using markdown bold syntax (word), which preserved our existing formatting system. This was our first insight: AI needs guidance on system context that isn’t obvious from the code alone.
Continue reading “How We Used Claude to Implement Text Synchronization Feature of Videocrawl”Giving Summary Generation Some Agency
One of the most common use cases of LLMs is summary generation. I have worked on multiple systems where we have summarized different kinds of documents – word, pdf, text, web pages, call transcripts, and video transcripts. I am building Videocrawl where we generate summaries of video content. In almost all the summary use cases I have implemented, we have gone with a static summary prompt where we instruct the LLM to generate a summary in a specific format. In my recent work, I have been playing with the idea of giving some agency to the summarizer so that we can generate dynamic summarization prompts. In this short post, I will share my approach.
Let’s make it concrete. Let’s assume that we want to summarize Search R1 paper. This paper covers how we can train LLMs to reason and leverage search engines for reinforcement learning.
Continue reading “Giving Summary Generation Some Agency”New Videocrawl Feature: Tracking Video Progress
We’ve implemented a smart video progress tracking system in https://www.videocrawl.dev/ that remembers your watching position across sessions. Now when you close a tab or navigate away from a video, you’ll be able to pick up right where you left off when you return.
The feature includes:
- A visual progress bar showing how much of the video you’ve watched
- Automatic resumption from your last position when returning to a video
- Persistent progress tracking across browser sessions
How I Built Videocrawl’s Screenshot Feature with Claude
I am building Videocrawl (https://www.videocrawl.dev/), an AI companion app for videos. The application aims to improve my learning experience while watching videos. Most of my feature ideas come from using the application, identifying gaps in the experience, implementing solutions, testing them in production, learning from actual usage, and then making further improvements. This development cycle continues iteratively. I use LLMs for writing most of the code, primarily relying on Claude for my chat-driven development workflow.
Videocrawl works by processing a YouTube video URL that you provide. We then present a side-by-side view with the video on the left and various LLM tools (clean transcript, summary, chat, and FAQs) on the right, as shown below. You can customize the layout based on your workflow preferences.
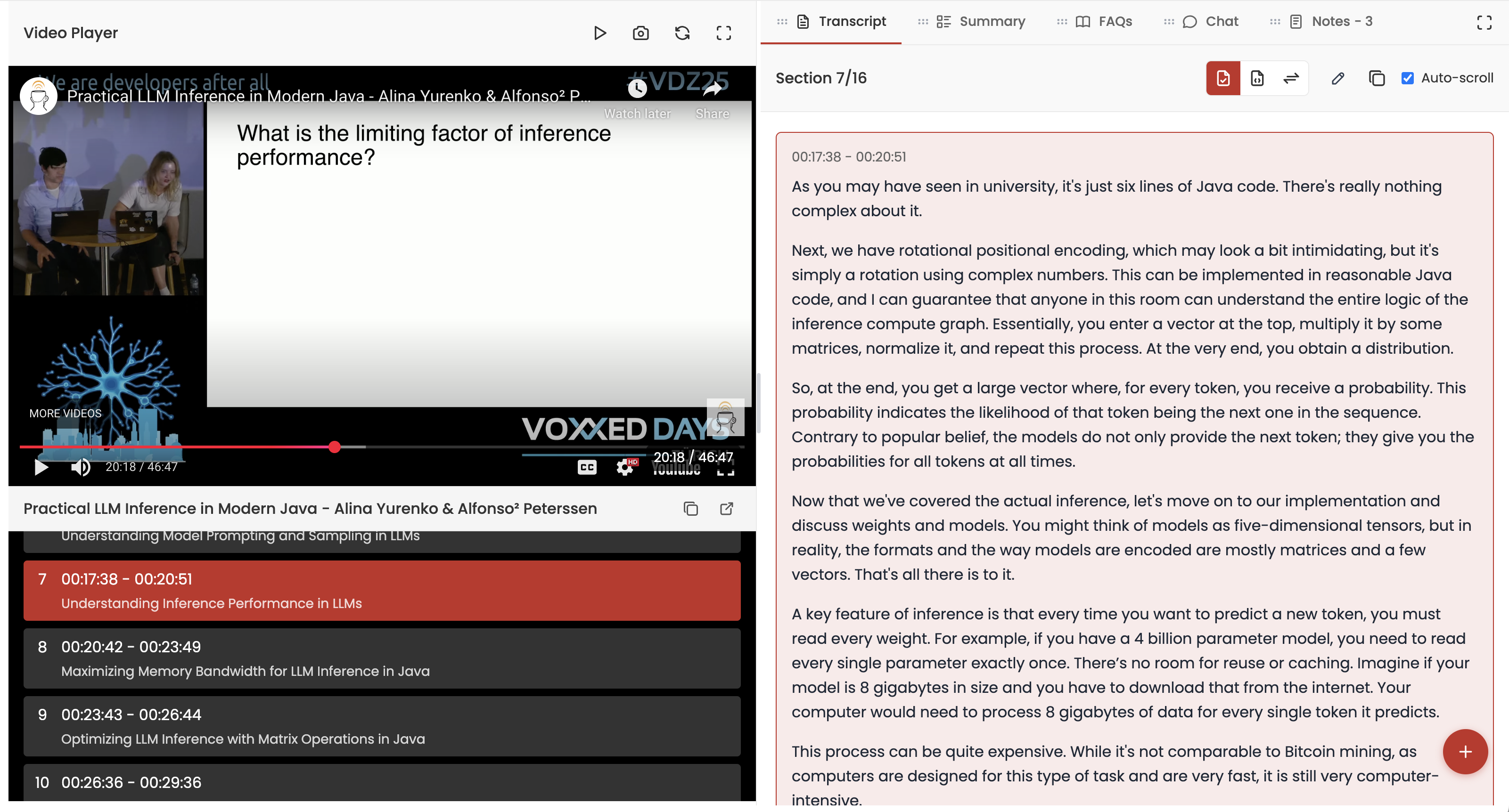
One feature I recently wanted to add was the ability to take a screenshot of the current video frame and save it as a note. We already supported text-based notes, so this seemed like a natural extension.
The concept was straightforward: when the user presses a camera button or uses a keyboard shortcut, we capture the current video frame and save it to their notes. Without LLMs, I would likely have avoided implementing such a feature, as it would require extensive research and trial-and-error. However, with LLMs, I felt confident that I could successfully attempt this implementation.
Continue reading “How I Built Videocrawl’s Screenshot Feature with Claude”Talk: AI Engineering at Jane Street
I watched AI Engineering at Jane Street talk yesterday. The talk offers many practical insights on how a good and mature engineering organization like Jane Street are using LLMs in their development process. My notes from the talk below:
- Jane Street decided to train their own model. They had to because most of the shelf large language models are not proficient with OCaml due to the limited amount of training data available. This makes it difficult to find suitable off-the-shelf tools that can effectively work with OCaml code.
- They took inspiration from a paper by Meta – AI-assisted Code Authoring at Scale. This paper detailed the results of fine-tuning a model specifically for use with Hack, a programming language similar to OCaml in that it is primarily used at one company and not widely adopted outside of that company. After reading this paper, Jane Street became more convinced about the potential of training models, which led them to explore the idea of replicating the results for their own use with OCaml. However, they soon realized that achieving good outcomes would require more than just taking an off-the-shelf model and showing it their code; they needed to collect numerous examples that aligned with their specific goals.
- Jane Street collects training data through a method called workspace snapshotting, where they take snapshots of developer workstations throughout the day. This allows them to capture changes and build statuses, which can then be used to train their models effectively. This was an interesting approach to collecting data. It looks like an expensive and complex approach for creating dataset. They had to do this because they were not able to use pull request and commit data to generate this data. Some of the challenges they mentioned in the talk:
- The feature descriptions used in their internal code review system (Iron) are not written in the same way as prompts that a developer would use in an editor.
- Features can be very large (e.g., 500 to 1000 lines), which complicates their use as training data. Smaller, isolated changes are needed for effective training .
- Commits are not isolated changes and lack descriptions, making them less useful for training purposes.
- They aligned the model’s outputs with human standards of good code through reinforcement learning. This involves verifying that the generated code can be parsed, type-checked, and passes tests when applied to the codebase.
- They also had to build their own code editor integrations. They use sidecare proxy/application to manages context, constructs prompts, and monitors build status for the editor integrations. It allows for seamless updates and changes without requiring individual editor modifications, enhancing the overall developer experience. They collect editor metrics to figure out the latency and effectiveness of the diffs generated by this model.
You can watch the video on Videocrawl – https://www.videocrawl.dev/studio?url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3D0ML7ZLMdcl4. Videocrawl is an AI companion application that improves the learning/watching experience.
