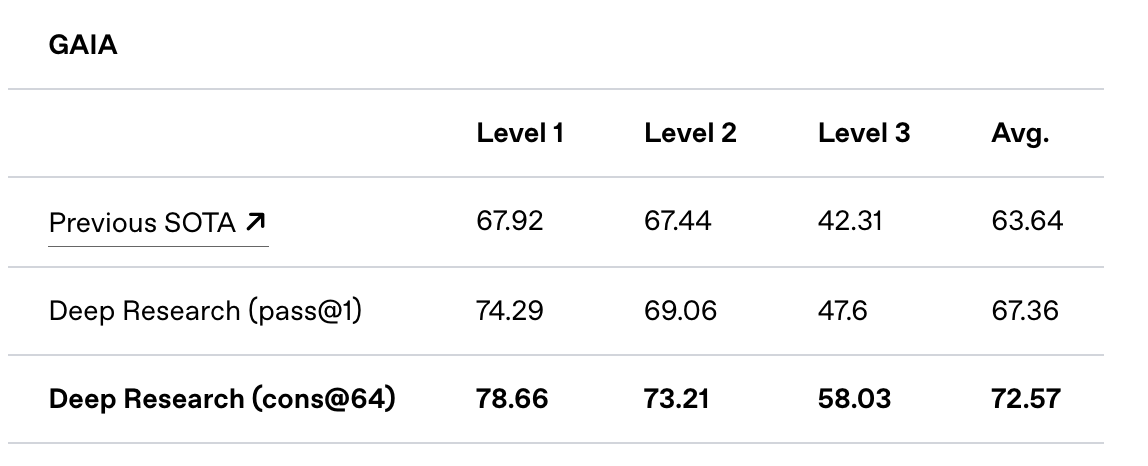
Anthropic released Claude 3.7 sonnet yesterday and I am liking vibes of it in my coding related tasks. Claude 3.7 Sonnet is a reasoning model like OpenAI o1/o3, Deepseek R1, Grok 3, and Google Gemini 2.0 Thinking.
I asked Claude 3.7 Sonnet to generate SVG visualization of Maha Kumbh. Kumbh Mela is an important Hindu pilgrimage, celebrated approximately every 6 or 12 years, correlated with the partial or full revolution of Jupiter. A ritual dip in the waters marks the festival.
I know we should use an image model but I wanted to see how far we can go with SVG with current reasoning models.
Below is the prompt
Generate an SVG illustration of the Maha Kumbh Mela, capturing its spiritual essence and vibrant atmosphere. The scene should include:
- Naga Sadhus (holy men) with ash-covered bodies and matted hair, some meditating and others engaging in rituals.
- Priests performing traditional Hindu ceremonies with sacred fire (yagna) and offering prayers.
- Devotees of various ages taking a holy dip in the river, expressing devotion and spiritual connection.
- People with folded hands praying to Lord Shiva, some with rudraksha beads and others offering milk or flowers.
- A grand backdrop of temple structures, flags, and colorful tents representing the spiritual congregation.
- Include iconic elements like tridents (trishul), damaru (drum), and Om symbols to reinforce the devotion to Lord Shiva.
Ensure the composition is detailed, with intricate line work and vibrant color contrasts to reflect the grandeur and sanctity of Maha Kumbh.
Below is the output of Claude 3.7 Sonnet with Extended Thinking. It thought for 4 seconds and generated below.

I also tried Grok3 as well. I had to tell it multiple times to generate SVG code. It defaulted to explanation with no code. After multiple tries this is what it generated.

Lastly, I tried OpenAI o3 mini. It generated following SVG.
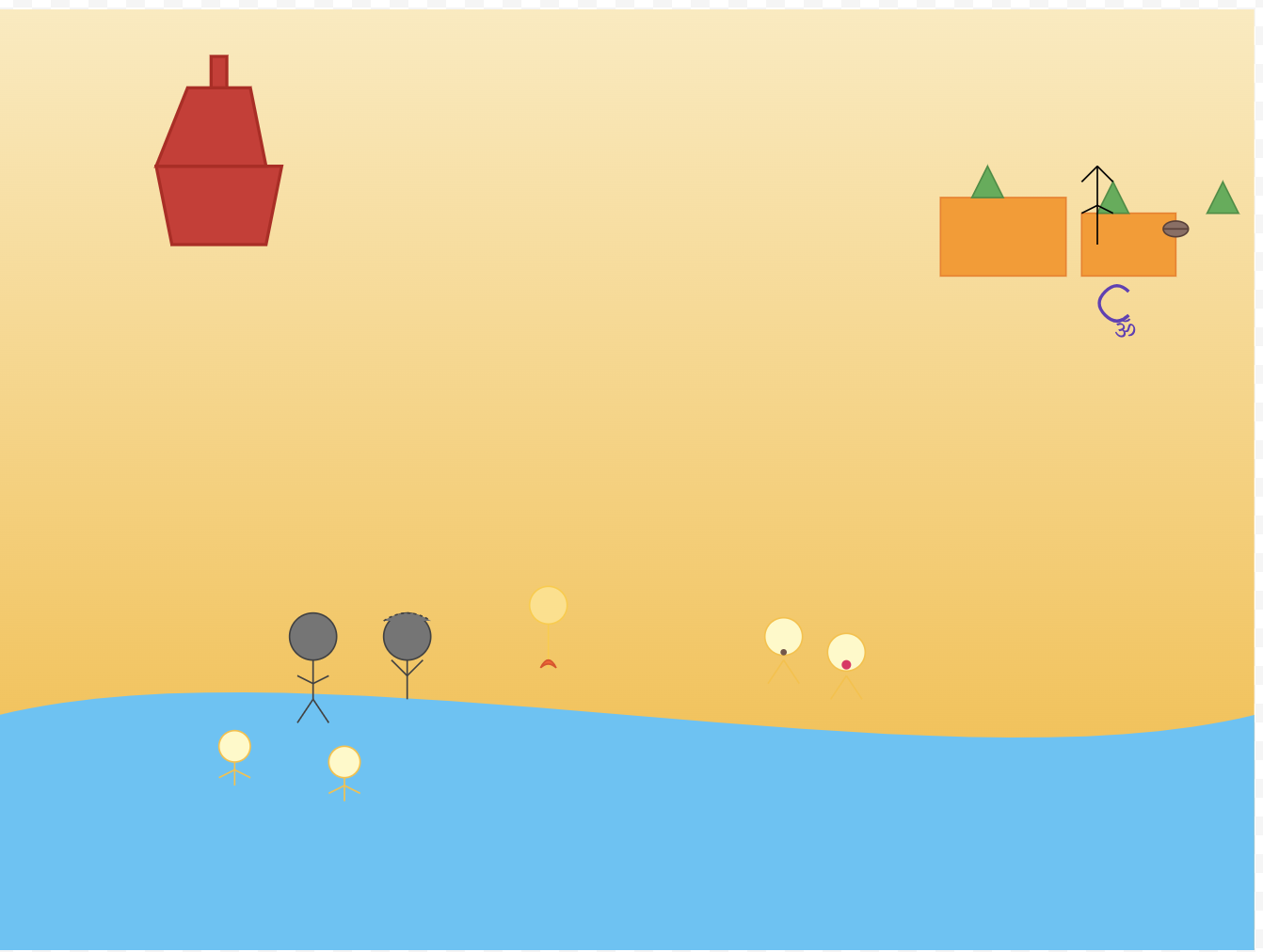
I liked Claude 3.7 Sonnet version. I think it captured few things well like Shivling.