I was reading Concise Thoughts: Impact of Output Length on LLM Reasoning and Cost paper today and thought of applying it to a problem I solved a couple of months back. This paper introduced the Constrained Chain of Thought (CCoT) prompting technique as an optimization over Chain of Thought Prompting.
Chain of Thought prompting is a technique that encourages LLMs to generate responses by breaking down complex problems into smaller, sequential steps. This technique enhances reasoning and improves the model’s ability to arrive at accurate conclusions by explicitly outlining the thought process involved in solving a problem or answering a question.
When using Zero-shot CoT technique, adding the line “Let’s think a bit step by step” to the prompt encourages the model to first generate reasoning thoughts and then come up with an answer. In Zero-shot CCoT, the prompt is changed to limit the number of words, such as “Let’s think a bit step by step and limit to N words.” Here, N can be any suitable number for your problem.
The paper showed results with N being 15, 30, 45, 60, and 100. CCoT was equal or better than CoT for N 60 and 100. As mentioned in the paper, CCoT technique works with large models but not with smaller ones. If CCoT works as written in the paper, it leads to improved latency, less token usage, more coherent responses, and reduced cost.
One of the interesting LLM use cases I solved lately was building RAG over table data. In that project, we did extensive pre-processing of the documents at the ingestion time so that during inference/query time, we first find the right table in the right format and then answer the query using a well-crafted prompt and tools usage.
In this post, I will show you how to do Question Answering over a single table without any pre-processing. We will take a screenshot of the table and then use OpenAI’s vision model (gpt-4o and gpt-4o-mini) to generate answers using three prompting techniques: plain prompting, CoT (Chain of Thought) prompting, and CCoT (Constrained Chain of Thought) prompting.
Let’s look at our example table. The below table is from the HDFC Bank Fees and Charges document. The PDF has multiple tables. Here, I am showing a single table to keep things simple.

One of the interesting questions we want to answer from this table is: “I have a Savings Max Account and my account balance is Rs 10,000. What will be my account service charge?” The model first has to find that the AMB (Average Monthly Balance) for a Savings Max Account is Rs 25,000, then it has to calculate the shortfall (25,000 – 10,000 = 15,000; 6% of 15,000 = 900), finally, since 600 is lower than 900, the charge is Rs 600.
Let’s write a simple Python function that calculate charge using the three prompting techniques we discussed above. We are using OpenAI python client in the code below. You can install it using pip install openai.
from openai import OpenAI
import base64
import time
client = OpenAI()
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def calculate_charge(prompt, img_path='./images/table.png', model='gpt-4o', detail='high'):
start_time = time.time()
response = client.chat.completions.create(
model=model,
temperature=0.0,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{encode_image(img_path)}", "detail": detail}
}
]
}
]
)
end_time = time.time()
elapsed_time = end_time - start_time
total_time = f"{elapsed_time:.4f} seconds"
return {
"model": model,
"response": response.choices[0].message.content,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.total_tokens - response.usage.prompt_tokens,
"execution_time": total_time
}
Let’s start with plain prompting.
result = calculate_charge(
prompt="I have a Savings Max Account and my account balance is Rs 10000. What will be my account service charge?")
result
It generates correct result without any advanced prompting technique. This is pretty good considering we used plain prompting without any examples or elaborate instructions. Later in the post, we will run with multiple values of account balance to see how it performs.
{
"model": "gpt-4o",
"response": "For a Savings Max Account, the Average Monthly Balance (AMB) requirement is ₹25,000. If your account balance is ₹10,000, you are short by ₹15,000.\n\nThe non-maintenance charge is either 6% of the shortfall or ₹600, whichever is lower.\n\n1. Calculate 6% of the shortfall:\n \\[\n 6\\% \\text{ of } ₹15,000 = 0.06 \\times 15,000 = ₹900\n \\]\n\n2. Compare ₹900 with ₹600:\n - ₹900 (6% of the shortfall)\n - ₹600 (fixed charge)\n\nSince ₹600 is lower than ₹900, the non-maintenance charge will be ₹600.\n\nTherefore, your account service charge will be ₹600.",
"input_tokens": 1136,
"output_tokens": 166,
"execution_time": "6.4516 seconds",
}
Based on the token usage per call cost with gpt-4o model is $0.0082. This means in 1 USD we can make 122 calls.
Now, let’s try with CoT.
result = calculate_charge(
prompt="I have a Saving Max Account and my account balance is Rs 10000. What will be my account service charge? Let's think a bit step by step.")
result
It also calculated correct result. It is shown below.
{
"model": "gpt-4o",
"response": "To determine the account service charge for your Saving Max Account with a balance of Rs 10,000, follow these steps:\n\n1. **Identify the Minimum Balance Requirement:**\n - For a Saving Max Account, the Average Monthly Balance (AMB) requirement is Rs 25,000 for Metro, Urban, Semi Urban, and Rural locations.\n\n2. **Calculate the Shortfall:**\n - Your current balance is Rs 10,000.\n - The shortfall from the required AMB is Rs 25,000 - Rs 10,000 = Rs 15,000.\n\n3. **Determine the Service Charge:**\n - The service charge is 6% of the shortfall or Rs 600, whichever is lower.\n - Calculate 6% of the shortfall: 6% of Rs 15,000 = 0.06 * 15,000 = Rs 900.\n\n4. **Compare the Calculated Charge with the Fixed Charge:**\n - The calculated charge is Rs 900.\n - The fixed charge is Rs 600.\n - The lower amount between Rs 900 and Rs 600 is Rs 600.\n\nTherefore, the account service charge for your Saving Max Account with a balance of Rs 10,000 will be Rs 600.",
"input_tokens": 1144,
"output_tokens": 263,
"execution_time": "7.4897 seconds",
}
Based on the token usage per call cost with gpt-4o model is $0.0097. This means in 1 USD we can make 103 calls. Also, latency is higher compared to plain prompting.
Now, let’s finally use CCoT prompting technique. Can it give lower latency and lower cost while still giving the correct result? Let’s find out.
result = calculate_charge(
prompt="I have Saving Max Account and my account balance is Rs 10000. What will be my account service charge? Let's think a bit step by step and limit the answer length to 100 words.")
result
It also produced correct result as shown below but at increased latency.
{
"model": "gpt-4o",
"response": "For a Savings Max Account, the Average Monthly Balance (AMB) requirement is Rs 25,000. Your current balance is Rs 10,000, resulting in a shortfall of Rs 15,000. The non-maintenance charge is 6% of the shortfall or Rs 600, whichever is lower. \n\n6% of Rs 15,000 = Rs 900.\n\nSince Rs 600 is lower than Rs 900, the service charge will be Rs 600.",
"input_tokens": 1152,
"output_tokens": 99,
"execution_time": "8.4352 seconds",
}
Based on the token usage per call cost with gpt-4o model is $0.0072. This means in 1 USD we can make 138 calls.
What will happen if we reduce the output length to 50 words. Will we still get correct answer? Let’s find out.
result = calculate_charge(
prompt="I have Saving Max Account and my account balance is Rs 10000. What will be my account service charge? Let's think a bit step by step and limit the answer length to 50 words.")
result
It produced correct results again.
{
"model": "gpt-4o",
"response": "For a Saving Max Account with a balance of Rs 10,000, the shortfall is Rs 15,000. The service charge is 6% of the shortfall (Rs 900) or Rs 600, whichever is lower. Therefore, the charge is Rs 600.",
"input_tokens": 1152,
"output_tokens": 59,
"execution_time": "5.9517 seconds",
}
Based on the token usage per call cost with gpt-4o model is $0.0066. This means in 1 USD we can make 152 calls.
As you can see from the above two examples, CCoT leads to lower cost, more throughput per dollar, and lower latency.
By evaluating just one query, we cannot be sure that CCoT works for all user queries. So, you should build an extensive automated test suite and then make the decision whether CCoT works for you or not. You should also experiment with multiple output lengths to see what works for you.
So far things look promising. Let’s build a test suite with 10 examples and then see if we are still getting correct results.
Below is the code that I wrote for executing 10 examples. Each example will be executed againt three prompting techniques. So, in total we will make 30 OpenAI API calls.
model = 'gpt-4o'
account_balances = [10000, 13000, 1000, 1312, 20000, 24000, 24500, 100000, 23900, 22000]
expected_results = [600, 600, 600, 600, 300, 60, 30, 0, 66, 180]
results = []
prompt_templates = [
{
"prompt": "I have Saving Max Account and my account balance is Rs {account_balance}. What will be my account service charge?",
"technique": "plain"
},
{
"prompt": "I have a Saving Max Account and my account balance is Rs {account_balance}. What will be my account service charge? Rs. 600 is maximum service charge. Let's think a bit step by step.",
"technique": "CoT"
},
{
"prompt": "I have Saving Max Account and my account balance is Rs {account_balance}. What will be my account service charge? Rs. 600 is maximum service charge. Let's think a bit step by step and limit the answer length to 50 words.",
"technique": "CCoT"
}
]
execution_count = 1
for prompt_template in prompt_templates:
for account_balance, expected_result in zip(account_balances, expected_results):
print(f"Executing {execution_count}")
execution_count += 1
prompt = prompt_template['prompt'].replace("{account_balance}", str(account_balance))
technique = prompt_template['technique']
result = calculate_charge(prompt, model=model)
result['technique'] = technique
result['account_balance'] = account_balance
result['prompt'] = prompt
result['expected_result'] = expected_result
results.append(result)
Below is the output in table format. With the gpt-4o model, we got correct answers with all three prompting techniques. The CCoT technique had the lowest latency and consumed the fewest tokens.
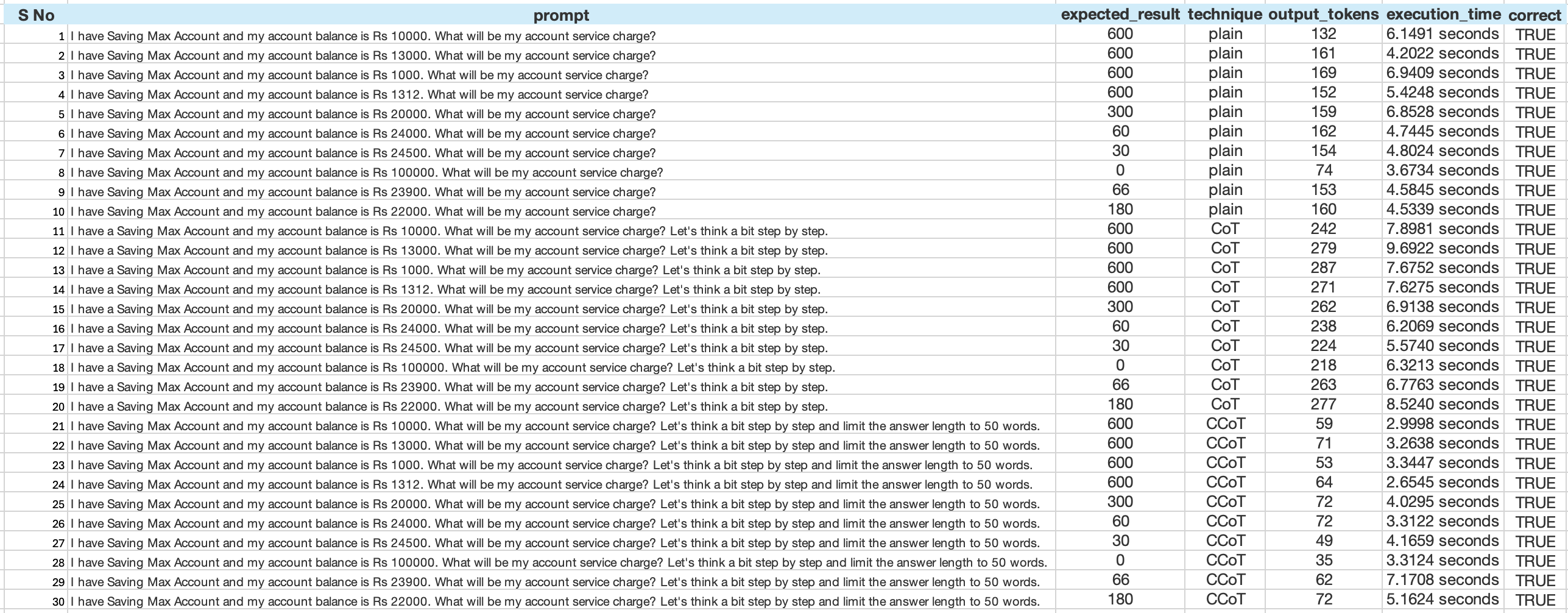
With plain prompting, we consumed a total of 1476 output tokens. Plain prompting cost a total of $0.0789 for 10 OpenAI calls.
With CoT prompting, we consumed a total of 2561 output tokens. CoT cost a total of $0.0956 for 10 OpenAI calls.
With CCoT prompting, we consumed a total of 609 output tokens. CCoT consumed 60% fewer output tokens compared to plain prompting and close to 80% fewer output tokens compared to CoT. CCoT cost a total of $0.0667 for 10 OpenAI calls.
CCoT looks like a promising optimization technique.
Let’s run the same experiment with gpt-4o-mini model. We only have to change the model variable in our Python script.
Below is the same table but this time with gpt-4o-mini model. I have removed execution time column as it follows the same trend.
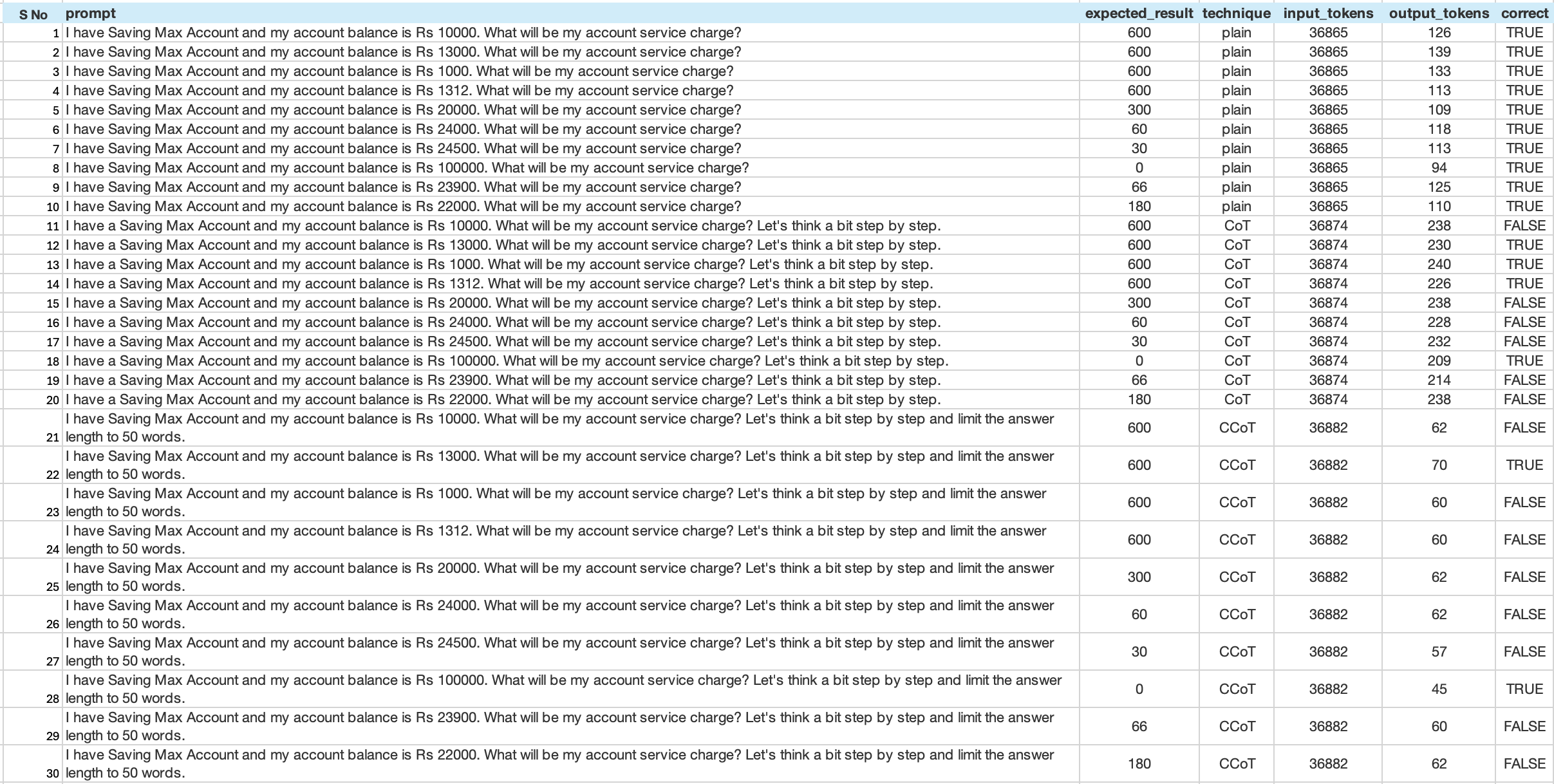
Interesting things to note from the above results:
- Plain prompting got all answers correct.
- With the CoT technique, we got 4 questions right and 6 questions wrong. The reason for all the wrong answers was that the model assumed Rs 600 was the minimum service charge, so it picked the one that was bigger.
- With the CCoT technique, we got only 2 questions right while 8 questions were wrong. There were two reasons for the wrong results: 1) it didn’t consider the minimum service charge; it only multiplied 6% by the shortfall. 2) In some cases, it assumed Rs 600 was the minimum service charge, so it picked the one that was bigger.
- Input token calculation is different for the
gpt-4o-minimodel compared togpt-4o. With the mini model, we consumed close to 36,000 tokens, whereas with gpt-4o, we consumed only 1200 tokens. The reason for this is that OpenAI has kept the image input price the same. So, they increased the number of input tokens in thegpt-4o-minito use the same per million token price.
We can improve the results by making couple of changes to our CoT and CCoT prompt.
- We instructed the model that Rs 600 is the maximum service charge
- We increased the answer length from 50 words to 100 words
prompt_templates = [
{
"prompt": "I have Saving Max Account and my account balance is Rs {account_balance}. What will be my account service charge?",
"technique": "plain"
},
{
"prompt": "I have a Saving Max Account and my account balance is Rs {account_balance}. What will be my account service charge? Rs. 600 is maximum service charge. Let's think a bit step by step.",
"technique": "CoT"
},
{
"prompt": "I have Saving Max Account and my account balance is Rs {account_balance}. What will be my account service charge? Rs. 600 is maximum service charge. Let's think a bit step by step and limit the answer length to 100 words.",
"technique": "CCoT"
}
]
Let’s run the script again and see the results.
This time we got all answers correct with gpt-4o-mini model as well.

Overall, I am surprised by how well plain prompting worked. You should start with that for your use case. Then, if that doesn’t work, try CCoT, and finally, if that also doesn’t work, use CoT.
Discover more from Shekhar Gulati
Subscribe to get the latest posts sent to your email.

Hi Shekhar, I am wondering how would this work if simply prompt, “I have Saving Max Account and my account balance is Rs {account_balance}. Dont be verbose, just give me the answer”
If the answer is incorrect, we can try slightly modified version to reduce the token cost “I have Saving Max Account and my account balance is Rs {account_balance}. Think deeply, but dont be verbose, just give me the answer”
Hi Selva,
I tried your suggestion. Model does not perform any calculation. It respond with `You do not meet the AMB requirement for the Savings Max Account.`
Interesting. Thanks for trying, Shekhar.